

Gemini Omni: Why the Era of Single-Format AI Is Officially Over?
Introduction
For three years, building anything with AI media basically meant chaining tools together. You wrote a script with one model, made visuals with another, produced a video with a third, and then topped it off with audio from a fourth. Every step sat in its own kind of silo, with its own little quirks, its own context that somehow got fuzzy in the handoff. That whole era sort of ended on May 19, 2026, at Google I/O.
Gemini Omni is Google’s first real “any-to-any” multimodal model, and it quietly changes the whole math. It can take in text, audio, images, and video all at the same time, doing reasoning across formats inside one unified engine instead of treating each one like a separate problem. As Google CEO Sundar Pichai put it, Omni can “create anything from any input.” For anyone whose job touches content, marketing, or media, this isn’t a small upgrade. It’s more like a structural shift for how creative work gets assembled and iterated.
Here’s the deal on what Gemini Omni actually is, how it works in practice, what it means for your content strategy, and the real limitations that sit underneath the launch-day hype.
What Gemini Omni Actually Is?
Until May 2026, Google’s AI media stack ran with separate models for each job, like Veo 3.1 for video, Imagen for images, Nano Banana Pro for editing, and Lyria for music. Getting to a finished video meant you had to stitch things together by hand, which kinda kills the flow, because context gets lost at every single handoff.
Gemini Omni sorta collapses all that into one system. It’s a unified multimodal model that takes text, image, audio, and video in basically any mix inside one prompt, then it reasons across all of that to generate its output. It’s built on Gemini’s reasoning plus a real-world knowledge stack, so it keeps context shared across every modality instead of treating each piece like an isolated little errand.
Here is the shift visualized:
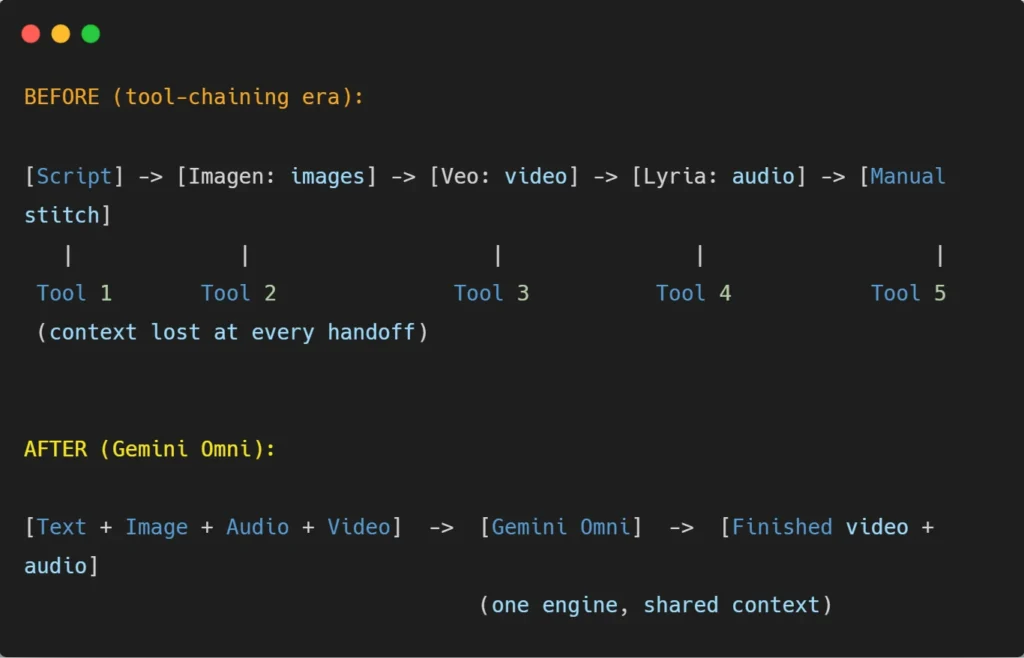
The first model in the family, Gemini Omni Flash, started rolling out the same day it was announced. It accepts any combination of inputs and produces video output, complete with synchronized audio, in roughly 10-second clips at launch.
This is the natural evolution of the multimodal AI race we have been tracking, including the recent Claude Opus 4.8 vs GPT-5.5 vs Gemini comparison, where multimodal capability is becoming a core battleground between the major labs.
How Gemini Omni Works: Any Input, Unified Output?
The “any-to-any” philosophy is what sets Gemini Omni apart.
Here is what that means in practice.
What You Can Feed It
- Text: Describe the scene, the action, the mood, the dialogue.
- Images: Reference photos for characters, products, styles, or settings.
- Audio: Voice samples, music, sound effects to guide the output.
- Video: Existing clips to edit, extend, or transform.
- You combine any of these in a single prompt, and Omni reasons across all of them together. Want a video that matches a reference photo’s character, follows a text script, and syncs to an uploaded audio track? That is one prompt, not four separate tool sessions.
What It Produces
- At launch, Gemini Omni Flash outputs video clips up to 10 seconds long with synchronized audio. Google has confirmed that image and audio output modalities are on the roadmap but not part of the initial release. The 10-second cap is expected to expand over time.
The Standout Features
- Conversational editing: This is the headline interaction model. Instead of regenerating from scratch, you refine through natural dialogue. “Make the lighting warmer.” “Change the camera angle.” “Have the character turn left.” The scene keeps its prior context across each turn.
- Character consistency: Characters introduced in one shot retain their face, clothing, and voice across cuts and edits within the same conversation, without re-uploading references.
- World model architecture: Google built Omni on a “world model” approach designed for physical realism, object permanence, and temporal consistency, addressing the uncanny glitches that plagued earlier AI video.
- SynthID watermarking: Every clip carries Google’s invisible AI provenance watermark, which survives common edits like re-encoding and resizing.
Where You Can Use Gemini Omni Right Now?
Gemini Omni Flash rolled out across several Google surfaces on launch day. Here is where it lives.
Available Now
- Gemini app: Google AI Plus, Pro, and Ultra subscribers get Omni video features as rollout reaches their accounts.
- Google Flow: Best suited for complete AI video and short-film workflows.
- YouTube Shorts and YouTube Create: Available at no cost, bringing Omni directly into short-form content creation for creators.
Coming Soon
- API access: Google has said developer and enterprise API access is arriving in the coming weeks. This is the release that matters most for businesses wanting to build Omni into their own products and workflows.
For teams thinking about how to integrate this kind of capability once the API lands, having a flexible, API-first architecture is what makes adopting new models like Omni fast and painless rather than a months-long rebuild.
Why This Changes Your Content Strategy Forever?
The marketing tagline on this announcement is bold: “Your content strategy will never be the same.” For once, that is not just hype.
Here is the real impact.
- Before Gemini Omni – A single marketing video required a script writer, a designer for visuals, a video editor, a voiceover artist or audio tool, and someone to stitch it all together. Days of work, multiple tools, multiple costs, and context lost at every handoff between specialists and software.
- After Gemini Omni, one person describes what they want, attaches a reference image and an audio track, and gets a finished video clip with synchronized audio in minutes. Then they refine it through conversation. The entire production pipeline collapses into a single intelligent engine.
The practical implications for content teams:
- Speed: Short-form video that took a day now takes minutes. For YouTube Shorts, social ads, and product demos, the velocity change is dramatic.
- Cost: The 10-second cap keeps per-generation cost low enough for mass distribution. Small teams can now produce video volumes that previously required agencies.
- Iteration: Conversational editing means you refine instead of restarting. Ten variations of an ad concept become a conversation, not ten separate projects.
- Accessibility: Non-technical creators can produce professional videos without learning complex editing software. The barrier to quality video collapses.
This shift mirrors a broader pattern we have documented across the industry in our analysis of how AI agents are replacing entire SaaS tools. When one intelligent system does what five specialized tools used to do, the entire workflow and the budget around it get rebuilt.
Gemini Omni vs Veo: Understanding the Split
A common point of confusion: did Omni replace Veo? The answer is partly, and understanding the split matters for teams deciding which to build on.
The Two Product Lines:
- Gemini Omni is multimodal-input, video-output. It lives in the Gemini app and YouTube, built on Gemini’s reasoning and world-knowledge stack. It is chat-native with conversational editing. Best for creators and consumer-facing short-form content.
- Veo 3.1 remains the video-first, developer-API surface on Vertex AI and Google Flow. It is a single-shot generation, video-in and video-out. Best for developers and enterprise video pipelines that need API access today.
Both ship alongside each other. Within the flagship Gemini app, Omni is now the default, but Veo continues to power developer and enterprise workflows on Vertex AI. Google is not killing Veo; it is positioning the two for different audiences.
Quick Comparison: Gemini Omni vs Veo 3.1
| Factor | Gemini Omni | Veo 3.1 |
|---|---|---|
| Input | Text, image, audio, video | Video-focused |
| Output | Video (+ audio) | Video |
| Editing | Conversational, turn-by-turn | Single-shot generation |
| Lives in | Gemini app, YouTube | Vertex AI, Google Flow |
| Best for | Creators, short-form content | Developers, enterprise pipelines |
| API today? | Coming in weeks | Available now |
If the table is tight on mobile, here is the simple version: Gemini Omni is the chat-native, multimodal-input model for creators in the Gemini app and YouTube. Veo 3.1 is the developer API model for building video pipelines on Vertex AI. Both are active; you pick based on whether you are creating content or building a product.
How Gemini Omni Compares to the Competition?
Gemini Omni is not the only multimodal video model in 2026, but yeah, its whole approach feels more separate. Here’s the honest competitive snapshot, with the messier edges included.
- Versus GPT-4o and kind of similar models: GPT-4o tends to do text, image, and audio well, but Gemini Omni goes further by doing native video generation inside the same unified system. So it’s pretty arguable that it’s the first real top-tier foundation model that has video output baked right into a reasoning-friendly multimodal core.
- Versus Seedance 2.0: Seedance is broadly viewed as the best “pure” video-generation model by May 2026. It can take up to 12 mixed assets, with native audio and music beat sync, hitting 1080p for about 4 to 15 seconds. Gemini Omni, though, is more about conversational, turn-by-turn editing, plus Google-style physics and real-world reasoning, but it’s currently capped at 10 seconds.
The strategic bet: Omni seems to prefer workflow over raw generation quality. That editing-first mindset is a different wager on where AI video goes next. If it works, Omni basically turns into a creative operating system. If not, it’s still a well-funded feature, and nothing more dramatic than that.
Either way, this unified multimodal architecture is clearly where the industry is steering, even if people pretend they’re not watching.
The Honest Limitations
Launch-day demos and production reality often diverge. Here are the real constraints to plan around.
- 10-second clip cap: At launch, Omni Flash produces clips up to 10 seconds. Longer-form content still requires stitching multiple generations. Google says this will expand, but no timeline is confirmed.
- Video-only output for now: Despite the “any-to-any” framing, the initial release only outputs video. Image and audio output are on the roadmap, but not yet available.
- API not ready yet: Developer and enterprise API access is “coming in the coming weeks.” Businesses wanting to build Omni into their products are waiting on this.
- Launch demo versus production fidelity: As independent evaluators benchmark Omni against Google’s physics-and-continuity claims, expect some gap between polished launch demos and real-world output. This is normal for frontier video models.
- Subscription gating: Full access requires Google AI Plus, Pro, or Ultra subscriptions, though YouTube Shorts access is free.
The disciplined approach to adopting any new AI capability is the same one we recommend across every deployment, and the same one that separates winners from the teams covered in our analysis of why AI projects fail: test it on your actual workflow, measure real results, and adopt based on outcomes rather than launch-day excitement.
What Businesses Should Do Now?
Gemini Omni is consumer-available today and enterprise-ready within weeks.
Here is the practical playbook.
- For Content and Marketing Teams – Start experimenting in the Gemini app or YouTube Create now. Test Omni on your actual short-form content needs: social ads, product demos, and explainer clips. Learn the conversational editing workflow. By the time the API lands, your team will already understand what Omni does well and where it falls short.
- For Developers and Product Teams – Watch for the API release in the coming weeks. Plan where unified multimodal generation fits in your product. The teams that move fastest when the API drops will have already mapped their use cases and built flexible integration layers.
- For Business Leaders – Recognize that the content production cost structure is shifting. Work that requires agencies or specialized teams is moving in-house and into single-prompt workflows. Budget and team structure should adapt to a world where one person plus AI does what a production team used to.
The Bigger Picture: Unified AI Is the Future
Let us take a step back and look at Gemini Omni signals to see where all of Artificial Intelligence is heading. The time when we used format and single-purpose models is coming to an end. Now the future belongs to systems that can understand and work with text, image, audio, and video all together as one connected intelligence. This is different from what we have, which are separate tools that are connected.
Google is trying something with Omni. They think that how we work is more important than how good the final results are. They believe that being able to edit and talk to the system and having all the information in one place will change the way creators work. Whether or not this works out, it is clear which direction things are going. Every major lab is working on multimodal models, and the businesses that change their plans for content, tools, and teams to fit this new reality will have an advantage over those that are still using single-purpose tools together.
Gemini Omni signals show us that Artificial Intelligence is moving towards a connected and unified system.
Conclusion: The Single-Format Era Is Over
Gemini Omni feels like a real turning point. For the first time, a top-tier AI model reasons across text, audio, image, and video in one unified setup, and somehow it can spit out finished video from whatever mix of inputs you throw at it, through a pretty natural conversation. The whole tool chaining era, where each media type basically sat in its own little silo, is getting, well, ending.
If you are a content creator, the speed and accessibility gains land right away. For developers, the API showing up in weeks is opening new product pathways, and yeah, it changes what you can build without waiting forever. For business leaders, the cost and the way content works are being rewritten, like in real time. Gemini Omni is not the final stop; that 10-second cap and the video-only output make that obvious, but it’s still a strong signal of the unified, multimodal future every business should start preparing for, now.
The age of single-format AI is over. The only real question left is not “will unified multimodal AI reshape content creation,” but rather how fast your team actually adapts to it.
About Orbilon Technologies
Orbilon Technologies is an AI development agency that helps companies build with the newest multimodal models, like Gemini Omni, Claude Opus 4.8, and GPT-5.5. We kinda design and deploy AI content pipelines, multimodal automation setups, custom AI agents, and also full enterprise AI blueprints across Google Vertex AI, AWS Bedrock, and Microsoft Foundry.
Our group has a 4.96 average rating across Clutch, GoodFirms, and Google, from clients in the US, Europe, and the Middle East. These include SaaS startups, financial services firms, healthcare platforms, and broader enterprise operations teams.
So, if you want to work with Gemini Omni and other multimodal AI models, just grab a free consultation. We will look over your content and your product goals, then give you a pretty candid implementation roadmap.
Want to Hire Us?
Are you ready to turn your ideas into a reality? Hire Orbilon Technologies today and start working right away with qualified resources. We will take care of everything from design, development, security, quality assurance, and deployment. We are just a click away.

