

Claude Opus 4.8 vs GPT-5.5 vs Gemini 3.5 Flash: Which One Should Your Business Actually Use?
Introduction
In a span of just five weeks, the three biggest AI labs each shipped a flagship model. OpenAI released GPT-5.5 on April 23, and Google launched Gemini 3.5 Flash at Google I/O on May 19. And Anthropic dropped Claude Opus 4.8 on May 28. So yeah, three frontier models, three kinds of different design mindsets, and one question every business leader ends up asking anyway: which one should we actually build on?
The honest answer is not “the best one.” It’s “the right one for your particular workload.” Claude Opus 4.8 vs GPT-5.5 vs Gemini 3.5 Flash isn’t some clean win-everything match. Opus 4.8 tends to lead in coding sharpness and reliability. GPT-5.5 shows up strong for terminal tasks and agentic execution. Gemini 3.5 Flash pretty much trounces the rest on speed and cost. Choose wrong, and you either overpay for the ability you don’t really require or you end up underpowering the parts of the job that actually matter.
This is the honest, no-hype comparison. Real benchmarks, real pricing, real-world verdicts, and a clear way to decide. No vendor gloss, just the numbers plus the judgment to use them.
The 30-Second Verdict
If you only read one section, read this one.
- Choose Claude Opus 4.8 if your work is coding-heavy, agentic, or requires reliable analysis where silent errors are expensive. It leads on SWE-Bench Pro and is the most honest model about its own uncertainty.
- Choose GPT-5.5 if your workflows live in the terminal, involve heavy CLI automation, or need the strongest computer-use and agentic execution. It is OpenAI’s most capable agentic model yet.
- Choose Gemini 3.5 Flash if speed and cost matter most, you run high-volume agentic tasks, or you need a strong multimodal understanding. It is 4x faster than other frontier models and dramatically cheaper.
Now, the details that justify those verdicts.
Meet the Three Contenders
Before the head-to-head, here is what each model actually is and where it comes from.
- Claude Opus 4.8 (Anthropic) – Released May 28, 2026, just 41 days after Opus 4.7. Anthropic’s most advanced publicly available model. Known for leading coding benchmarks and exceptional reliability, and being the most “honest” model about flagging its own uncertainty. Sits just below the restricted Mythos-class models in Anthropic’s lineup. This is the model we broke down in detail in our Claude Opus 4.8 deep dive.
- GPT-5.5 (OpenAI) – Released April 23, 2026, codename “Spud.” OpenAI’s first fully retrained base model since GPT-4.5. Natively omnimodal, with state-of-the-art agentic performance. Strongest in terminal coding, computer use, and long-horizon tool sequencing. The reigning champion for CLI-heavy and browser-automation workflows.
- Gemini 3.5 Flash (Google) – Released May 19, 2026, at Google I/O. The first model in Google’s new Gemini 3.5 family. Remarkably, this Flash-tier (fast and cheap) model now beats last year’s premium Gemini 3.1 Pro on coding and agentic benchmarks. It is the default model in the Gemini app and Google Search AI Mode, reaching billions of users. Built specifically for agentic, long-horizon tasks at high speed.
Benchmark Showdown: The Numbers
Here is where the three models actually stand. Note that each lab reports benchmarks at its preferred settings, so treat these as directional rather than perfectly apples-to-apples.
a. Coding and Agentic Benchmarks
| Benchmark | Opus 4.8 | GPT-5.5 | Gemini 3.5 Flash |
|---|---|---|---|
| SWE-Bench Pro (agentic coding) | 69.2% | 58.6% | Not lead |
| Terminal-Bench (CLI tasks) | 2nd | Wins | 76.2% |
| MCP Atlas (tool-use) | 77.3% | 68.1% | 83.6% |
| Agentic computing use | 83.4% | 78.7% | Strong |
| Multimodal (CharXiv) | Strong | Strong | 84.2% |
If the table is tight on your screen, here is the same data in plain language:
SWE-Bench Pro (real coding issues): Opus 4.8 leads decisively at 69.2%, ahead of GPT-5.5 at 58.6%. This is the benchmark that matters most for serious software engineering.
Terminal-Bench (command-line tasks): GPT-5.5 wins overall; Gemini 3.5 Flash hit 76.2%, beating last year’s Gemini 3.1 Pro. Opus 4.8 sits second here; it’s one relatively weak spot.
MCP Atlas (tool-use reliability): Gemini 3.5 Flash surprisingly leads at 83.6%, ahead of Opus 4.8’s 77.3%. Strong tool-use is now a Flash-tier capability.
Multimodal understanding (CharXiv): Gemini 3.5 Flash leads at 84.2%, reflecting Google’s traditional strength in multimodal AI.
The pattern: Opus 4.8 owns issue-level coding, GPT-5.5 owns terminal and CLI, and Gemini 3.5 Flash punches far above its price tier on tool-use and multimodal work.
b. Visual: SWE-Bench Pro (Coding) Scores
Here is the most important coding benchmark visualized, so the gap is easy to see at a glance:
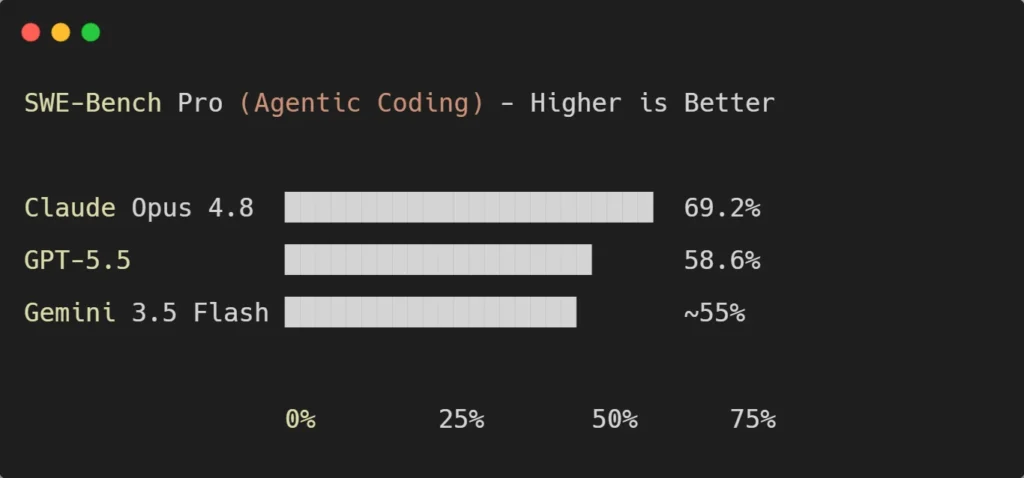
For pure software engineering, Opus 4.8’s lead is real and meaningful. But remember: this is one benchmark. The full picture below shows where each model genuinely wins.
Pricing: The Cost Math That Decides Most Deployments
For high-volume production workloads, pricing often matters more than a few benchmark points. Here is where the three models land.
Price Per Million Tokens:
| Model | Input | Output | Speed Note |
|---|---|---|---|
| Claude Opus 4.8 | $5.00 | $25.00 | Standard tier |
| GPT-5.5 | $5.00 | $30.00 | Standard tier |
| Gemini 3.5 Flash | $1.50 | $9.00 | 4x faster output |
In plain language for mobile readers:
Claude Opus 4.8: $5 input, $25 output per million tokens. Premium pricing for premium coding and reliability.
GPT-5.5: $5 input, $30 output per million tokens. The most expensive output of the three.
Gemini 3.5 Flash: $1.50 input, $9 output per million tokens. Roughly one-third the cost of Opus 4.8 on input, and dramatically cheaper on output, while running 4x faster.
The cost gap is striking. For a workload processing 100 million input and 50 million output tokens monthly:
Opus 4.8: roughly $1,750/month GPT-5.5: roughly $2,000/month Gemini 3.5 Flash: roughly $600/month
That is a real difference. For high-volume agentic work where Gemini 3.5 Flash’s quality is “good enough,” the savings compound fast. One important note: Gemini 3.5 Flash’s pricing is actually 3x more expensive than the previous Gemini 3 Flash ($0.50/$3), so Google is repositioning Flash as a serious agentic tier rather than just the cheap option.
Speed: The Underrated Decision Factor
Speed rarely makes headlines, but it shapes user experience and throughput more than most teams realize.
- Gemini 3.5 Flash is the clear speed champion at 4x faster output than other frontier models. For real-time applications, interactive tools, and high-throughput agentic loops, this is a genuine competitive advantage.
- Claude Opus 4.8 offers a fast mode at 2.5x speed (for $10/$50 per million tokens) and has a notably quick time-to-first-token, making it feel responsive in interactive use.
- GPT-5.5 has higher latency to the first token (around 3 seconds) but solid throughput once generation starts. Better suited to background agentic work than snappy interactive surfaces.
For customer-facing tools where every second affects experience, speed ranking matters: Gemini 3.5 Flash first, Opus 4.8 second (especially in fast mode), GPT-5.5 third.
Visual: Speed vs Cost Positioning
Here is how the three models position on the two factors that decide most high-volume deployments:
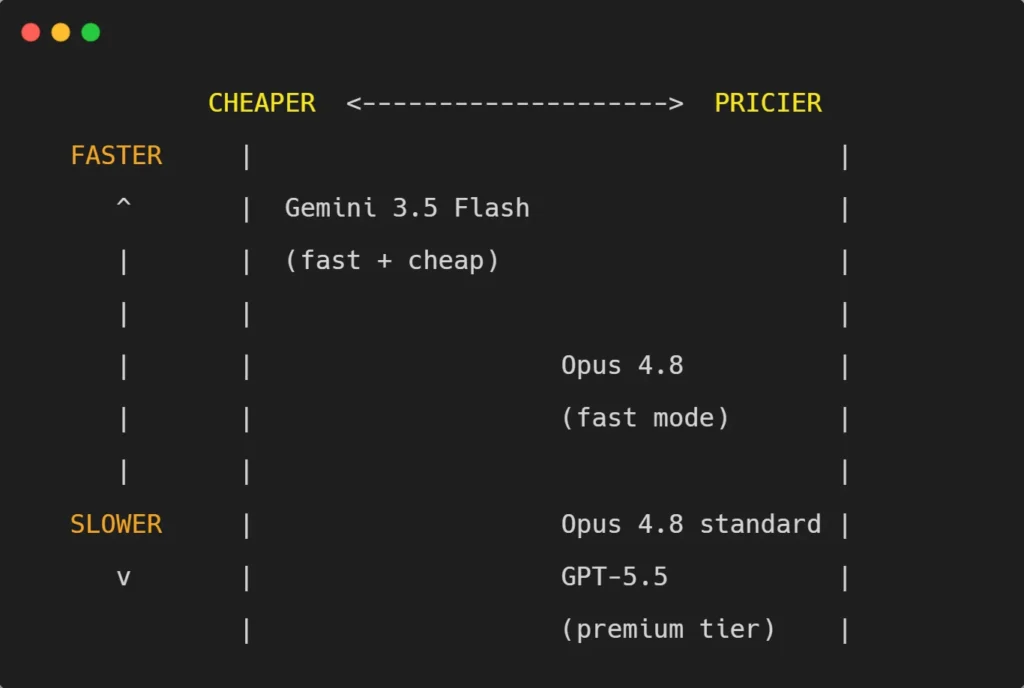
The takeaway: Gemini 3.5 Flash sits in the most attractive corner (fast and cheap) for high-volume work. Opus 4.8 and GPT-5.5 cost more but deliver depth where it matters. This is exactly why multi-model routing wins.
Which Model for Which Use Case?
This is where the Claude Opus 4.8 vs GPT-5.5 vs Gemini 3.5 Flash decision gets practical.
Here is the honest breakdown by workload.
- Software Engineering and Code Review – Winner: Claude Opus 4.8. SWE-Bench Pro at 69.2% plus the new Dynamic Workflows feature that handles codebase-scale migrations make Opus 4.8 the strongest choice for serious software work. For teams treating Claude Code as a co-engineer, this is the natural pick.
- Terminal and DevOps Automation – Winner: GPT-5.5. OpenAI’s model still leads terminal and CLI workflows. If your automation lives in the shell, GPT-5.5 edges out the competition.
- High-Volume Agentic Workflows – Winner: Gemini 3.5 Flash. At 4x speed and one-third the cost, Flash is ideal for agentic tasks running thousands of times daily where Opus-level reasoning is overkill. Its 83.6% MCP Atlas score proves it handles tool-use reliably.
- Reliable Business Analysis – Winner: Claude Opus 4.8. Its honesty advantage (4x less likely to let flaws pass unflagged) makes it the safest choice for legal, financial, and analytical work where silent errors are costly. This reliability is a core reason businesses choose Claude AI for production.
- Multimodal and Visual Work – Winner: Gemini 3.5 Flash. Google’s traditional multimodal strength shows in its 84.2% CharXiv score. For image, video, and document understanding, Flash leads.
- Customer-Facing Real-Time Apps – Winner: Gemini 3.5 Flash (speed) or Opus 4.8 fast mode (quality). Depends on whether you prioritize raw speed or response quality. Both beat GPT-5.5 on latency.
The Smart Strategy: Use More Than One
Here is what the most sophisticated teams actually do in 2026: they do not pick one model. They route each task to the model that handles it best.
A typical multi-model routing setup:
- Coding and code review go to Claude Opus 4.8.
- Terminal and DevOps automation goes to GPT-5.5.
- High-volume agentic tasks and customer-facing speed go to Gemini 3.5 Flash.
- Simple, high-volume routine work goes to even cheaper models like Claude Haiku 4.5 or Gemini Flash Lite.
This routing approach optimizes both cost and quality. Frontier models handle frontier tasks. Fast, cheap models handle routine volume. Total AI spend often drops 40-60% versus running everything on a single premium model. The architectural foundation that makes this practical is a clean, model-agnostic integration layer, which is exactly why API-first development matters so much for AI products in 2026.
Honest Limitations of Each Model
No model is perfect. Here are the real tradeoffs the announcements gloss over.
- Claude Opus 4.8 Limitations: Trails GPT-5.5 on terminal coding by roughly 3.6%. More expensive than Gemini 3.5 Flash. Can be verbose, which fills context faster and raises cost on long agentic runs.
- GPT-5.5 Limitations: The most expensive output pricing of the three at $30 per million tokens. Higher latency to first token. The “fails forward” pattern, where it confidently completes tasks that turn out subtly wrong.
- Gemini 3.5 Flash Limitations: Pricing tripled versus the previous Gemini 3 Flash, so it is no longer the budget option. As a Flash-tier model, it may not match Opus 4.8’s depth on the hardest reasoning tasks. Google’s ecosystem lock-in can be a factor for non-Google-Cloud teams.
This is the same disciplined evaluation that separates teams capturing real AI value from those covered in our analysis of why AI projects fail. The model choice matters far less than testing it against your actual workload before committing.
How to Choose: A Decision Framework
For technical leaders making the call, here is the practical framework.
- Step 1: Categorize your primary workload. Is it coding, terminal automation, high-volume agentic, analysis, or multimodal? Your dominant use case points to a default model.
- Step 2: Weigh cost against quality. If you process millions of tokens daily and quality is “good enough” with Flash, the cost savings are substantial. If precision matters more than price, Opus 4.8 or GPT-5.5 justify their cost.
- Step 3: Test on your actual tasks. Launch-day benchmarks are directional, not definitive. Run all three on a representative sample of your real work for two weeks. Measure accuracy, cost, and speed on tasks you actually do.
- Step 4: Consider multi-model routing. If different parts of your product have different needs, routing tasks to the best-fit model usually beats committing to one. The payback on routing infrastructure is typically 30-60 days.
- Step 5: Build for model flexibility. With frontier models now shipping every few weeks (Opus 4.8 came just 41 days after 4.7, and Gemini 3.5 Pro is expected in June), the smartest architecture lets you swap models without rewrites.
The Bigger Picture: What This Three-Way Race Signals
Step back, and you see this Claude Opus 4.8 vs GPT-5.5 vs Gemini 3.5 Flash race kinda tells you something about AI in 2026, not in a neat way but in a practical one.
First, the release cadence has picked up a lot. Three flagship models in five weeks. Each lab is under pressure to ship faster, and each new version adds meaningful capability while keeping costs flat or even lower, which is not always what people expect.
Second, the “cheap tier” is basically gone. Gemini 3.5 Flash tripled its price because Flash-tier models now deliver last year’s premium-tier capability. So the economics of AI are being re-shuffled across every provider, as the whole pricing map got redrawn overnight.
Third, specialization is starting to win more often. Opus 4.8 is for coding precision. GPT-5.5 leans into terminal execution. Gemini 3.5 Flash is about speed and cost. And no single model dominates everything, which means the smartest businesses build adaptable systems rather than betting everything on one vendor.
For most teams, the winning move in 2026 isn’t picking the single “perfect” model right now. It’s building AI products flexible enough to adopt each new release as it ships, routing tasks to the best-fit model, and continuously tracking real-world performance against real-world cost.
Conclusion: There Is No Single Winner, Only Best Fits
The Claude Opus 4.8 vs GPT-5.5 vs Gemini 3.5 Flash comparison really doesn’t crown just one champion because each lab did its own thing, and tuned for different priorities. Anthropic seemed to focus on the most steady coding and analysis behaviors, which is kind of the whole point. OpenAI went hard on terminal workflows and agentic execution, like, actually getting tasks done end to end. Google, meanwhile, built a fast, budget-friendly frontier-style model that still hits surprisingly strong, kind of a heavyweight for the price bracket.
For your business, though, the “right” pick depends on your workload, 100%. If you’re doing lots of coding and you can’t afford weird mistakes or brittle reasoning, then Opus 4.8 is the safer bet. If you’re living in the terminal, CLI automation, and tool-using chains, then GPT-5.5 tends to feel more natural. If you have high-volume stuff, you care about latency, and cost is always on the table, then Gemini 3.5 Flash is usually the smart, economical match. And for teams shipping real production AI, the best answer is often “use all three, intelligently routed.”
The model war is real, the competition stays intense, and the winners are typically the businesses that actually match each model to its strongest lane. Don’t just trust benchmarks, try all three on your actual work, measure outcomes, and keep your setup flexible enough to adapt when whatever comes next shows up, because in 2026, something better is always, literally, a few weeks away.
About Orbilon Technologies
Orbilon Technologies is a sort of AI development Agency that builds production systems across most major frontier models, including Claude Opus 4.8, GPT-5.5, and Gemini 3.5 Flash. We end up designing and deploying multi-model routing architectures, plus custom AI agents, agentic coding workflows, and full enterprise AI systems across AWS Bedrock, Google Vertex AI, and Microsoft Foundry.
Our team keeps a 4.96 average rating across Clutch, GoodFirms, and Google from clients across the US, Europe, and the Middle East, including SaaS startup crews, financial services firms, healthcare platforms, and enterprise operations teams.
If you are not sure which AI model fits your business exactly, we can help. Get a free consultation. We will look through your workloads, model the cost versus quality tradeoffs, and provide a straightforward recommendation, also including whether multi-model routing actually makes sense for you.
- Email: support@orbilontech.com
Want to Hire Us?
Are you ready to turn your ideas into a reality? Hire Orbilon Technologies today and start working right away with qualified resources. We will take care of everything from design, development, security, quality assurance, and deployment. We are just a click away.

