
AI Development in Raleigh - North Carolina | Orbilon Tech
AI Demos Are Free. Production AI Is What Triangle Buyers Actually Pay For.
AI Development in Raleigh – Every AI vendor in the country can show a working demo this week. Almost none can ship a system that survives the next six months in production — handling real users, real data, real edge cases, and the regulatory reviewers who are increasingly asking pointed questions about how the model works.
That gap between demo and production is the single most important thing a Raleigh AI buyer is evaluating, and the city is uniquely positioned to evaluate it.
The Research Triangle has built a deep AI bench. The IBM Quantum Computing Hub sits on NC State’s Centennial Campus. Pendo, the Raleigh-headquartered SaaS unicorn, has shipped Novus.ai — a product agent that connects directly to a customer’s codebase and instruments it automatically — and Pendo MCP, which pipes real-time product insights into Claude, ChatGPT, and Cursor, where engineers actually work.
Pryon, a Raleigh-based enterprise AI company, runs out of Centennial Campus alongside dozens of NC State research labs. Apple’s planned $1 billion+ Research Triangle Park campus is recruiting machine learning, AI, and software engineering roles at average minimum salaries above $187,000. Duke Institute for Health Innovation runs production AI projects across Duke Health. NC State stands up an AI research development unit specifically focused on positioning the university for large-scale AI-enabled research grants.
Buyers shaped by this ecosystem ask different questions than buyers in markets where AI is still treated as a marketing keyword. They want to know about evaluation harnesses, hallucination rates, prompt-injection defenses, token cost ceilings, and what happens when the upstream model provider deprecates an API. They want to see model cards, not Figma mockups.
For businesses looking for the best AI development company in Raleigh — one that ships AI cleared for Duke and UNC clinical review, NCDIT government-aware procurement, and the engineering scrutiny Pendo, Pryon, and the broader Centennial Campus startup ecosystem bring to every vendor evaluation — Orbilon Technologies delivers custom AI solutions in Raleigh end-to-end. LLM-powered systems, retrieval-augmented generation (RAG) pipelines, machine learning models, autonomous AI agents, and the production observability and cost-governance infrastructure these systems need to run for years instead of weeks.
The Model Selection Decision That Defines Every Raleigh AI Build
AI Development in Raleigh – Every serious AI engagement starts with a question web teams never have to ask, and mobile teams never face: which model does the system actually run on? Top AI developers in Raleigh treat this decision the way structural engineers treat a load-bearing wall — get it wrong and everything else has to be rebuilt.
There is no universal right answer. There is the right answer for your data, your latency budget, your regulatory posture, and how much it can cost per call.
- OpenAI (GPT-4.1, GPT-4o, GPT-4o mini). The right choice when broad reasoning quality matters most, when the team needs the strongest off-the-shelf coding and math performance, and when latency and ecosystem maturity (function calling, structured outputs, vision) outweigh other concerns. Higher per-token cost balanced against shorter time to working product.
- Anthropic Claude (Sonnet 4, Opus). The right choice when long-context reasoning, careful instruction following, and lower hallucination rates matter — especially for analysis, document understanding, and agentic workflows. Strong fit for healthcare-adjacent AI where careful, hedged answers beat confident wrong ones.
- Open-source models (Llama, Mistral, Qwen). The right choice when data sensitivity rules out external API calls, when on-premise deployment is a regulatory requirement, when the workload is large enough that hosting cost beats per-token cost, and when fine-tuning on proprietary data delivers compounding gains. The Triangle’s open-source-fluent engineering culture (rooted in Red Hat’s longstanding Raleigh presence) makes self-hosted Llama and Mistral deployments natural here.
- Specialty and small models. Embeddings (OpenAI text-embedding-3, Cohere, Voyage), reranking (Cohere Rerank), and small task-tuned models (Phi, Gemma) layered into systems where a flagship model would be overkill. Cost-aware Triangle buyers — especially those running thousands of inferences per day — increasingly demand this layered architecture.
- Custom fine-tuned models. The right choice when domain-specific terminology, output formatting, or behavior cannot be reliably elicited from a base model with prompting alone. Triangle biotech and clinical research teams running specialized analysis pipelines, and Centennial Campus startups with proprietary annotated datasets, are the typical users.
It’s a mistake to select a model based solely on the latest benchmark trends. In reality, production systems leverage multiple models – a primary model for complex reasoning, smaller models for high-volume tasks, and specialized models for embeddings – each chosen to optimally suit the specific requirements of each stage in the process.
Why Triangle AI Buyers Demand Evaluation Before They Sign Anything?
AI Development in Raleigh – The single biggest difference between Raleigh AI buyers and AI buyers elsewhere is that Triangle teams have been burned by demos. They have watched a model that looked confident in a sandbox produce dangerous nonsense in front of a real user. They now ask for evaluation harnesses before they ask about features.
This shapes how serious AI consulting in Raleigh actually works.
- Eval-first development is now standard practice. Frameworks like Ragas, DeepEval, Promptfoo, and custom evaluation harnesses built around the actual use case define quality before a single prompt goes into production. Healthcare AI for Duke, UNC, and the broader clinical research network is built this way out of necessity. Government-touching AI for NCDIT and state agencies is increasingly built this way because procurement reviewers are asking the right questions.
- Hallucination rates are measured, not assumed. Production AI systems shipped into the Triangle come with documented hallucination rates on representative test sets, with retrieval grounding metrics, citation accuracy scores, and refusal rates that buyers can verify before signing. Hire AI engineers in Raleigh who cannot tell you their hallucination rate on your specific data, and you have hired a demo team.
- Prompt-injection defenses are part of the threat model. Apps that take untrusted input and feed it to an LLM (customer support bots, document analyzers, agentic systems) face active prompt-injection attempts in production. Layered defenses — input filtering, output validation, structured output enforcement, sandboxed tool calls, and explicit authority boundaries — are baseline.
- Output verification is its own architecture layer. Production AI systems do not trust their own output. They validate JSON schemas, reject responses that violate business rules, route uncertain answers to humans, and log everything for after-the-fact review. The Triangle teams that have shipped real AI know this from scar tissue.
- Continuous evaluation runs in production, not just at design time. Drift detection, regression testing on prompt changes, A/B testing of model versions, and dashboards that show quality decay before users complain. Without this, AI systems silently degrade as models update upstream and data distributions shift.
The teams that ship AI in Raleigh treat evaluation as the deliverable, with the code that calls the model as the side product. The teams that get this backwards ship demos that crumble under contact with reality.
The Data Layer That Makes Every Production AI System Actually Work
The most common misconception about AI development is that the model is the system. The model is rarely the bottleneck. The data layer is. Custom AI solutions in Raleigh that survive contact with real users are the ones where the retrieval and grounding infrastructure was treated as the primary engineering investment.
- Retrieval-Augmented Generation (RAG) is the default architecture for knowledge-grounded AI. Vector databases (Pinecone, Weaviate, Qdrant, ChromaDB, pgvector) holding embeddings of the customer’s actual documents, protocols, scientific literature, code, or product knowledge. Hybrid retrieval combining dense vector search with keyword (BM25) search. Reranking layers (Cohere Rerank, cross-encoders) to surface the most relevant context. Citation trails that the user can audit.
- The chunking strategy quietly determines half the system’s quality. Naive fixed-size chunking destroys semantic coherence. Production systems use semantic chunking, overlap strategies tuned to the document type, parent-child retrieval where small chunks find context but the model sees larger surrounding passages, and document-aware preprocessing that preserves structure (headings, tables, code blocks).
- Embedding model choice has long-tail consequences. Different embedding models capture different relationships between concepts. The Triangle’s research-driven AI work — biomedical literature search at Duke, scientific paper retrieval at NC State, legal document analysis for state agencies — often demands domain-specific embeddings (BioBERT, SciBERT, e5-large) rather than general-purpose ones.
- Knowledge base curation is an underrated discipline. AI systems are only as good as the data they retrieve from. Production-grade builds include data cleaning pipelines, deduplication, version control on source documents, freshness monitoring, and automatic re-indexing as the underlying knowledge changes. NC State’s research labs and Triangle biotech firms generate corpora that need this kind of stewardship.
- Fine-tuning data needs the same rigor as fine-tuning code. When a base model isn’t enough, the training data — annotated examples, preference pairs for RLHF, evaluation sets — have to be curated to professional standards. Sloppy fine-tuning data produces sloppy models. The Triangle’s university research culture sets a high bar here.
The systems that ship cleanly in Raleigh treat the data layer as the product. The model is the renderer.
Safety, Privacy, and Cost Governance That Survive Real Procurement
AI compliance is its own category. It is not web compliance with a chatbot bolted on. The threat model is different, the failure modes are unique, and the procurement reviewers asking questions in the Triangle have learned to look in specific places.
- Prompt-injection resistance is now a required posture. Healthcare-adjacent AI, government-touching AI, and financial AI all face active attempts to manipulate models through user input. Defense layers — instruction hierarchy enforcement, user-input quarantining, structured-output schemas, tool-call authority boundaries, and output filtering — are baseline. Procurement reviewers who have read the latest OWASP LLM Top 10 ask about every one of these.
- PII detection and redaction run inline. Regulated AI workflows — clinical notes, customer support tickets, internal documents — pass through PII scrubbing before context reaches the model and again before output reaches the user. Microsoft Presidio, AWS Comprehend, and custom rule-based filters are all in the toolbox.
- HIPAA-aware AI architecture is non-negotiable for Triangle Healthcare. With Duke Health, UNC Health, WakeMed, and the broader Triangle clinical research ecosystem actively building AI into their workflows, AI vendors face Business Associate Agreements (BAAs), encrypted data flows, audit logging that meets HIPAA standards, and model deployment patterns that keep Protected Health Information out of training pipelines and external API calls.
- Audit trails are designed in, not added later. Every AI decision in a production system gets logged — input, retrieved context, model used, output, confidence signals, and downstream actions. Reviewers can trace any answer back to its source data and its decision path. This is what makes AI systems explainable in the regulatory sense, not just technically.
- Token cost governance is the new cloud cost governance. AI systems running thousands of inferences per day burn real money. Production builds ship with per-user, per-feature, and per-tenant cost ceilings, model-routing logic that uses cheaper models for easier requests, caching layers that prevent duplicate calls, and dashboards that flag cost anomalies before the monthly bill arrives. Our PromptBatch platform was built specifically to handle this layer.
- Model versioning and rollback work the same way as code. Production AI systems pin model versions, run shadow deployments of new versions against old ones, A/B test prompt changes, and roll back instantly when quality regresses. Without this, every upstream model update becomes a surprise.
The teams that ship AI cleanly into Raleigh treat safety, privacy, and cost as engineering problems with engineering solutions — not policy documents written after launch.
Web and Software Services for Baltimore's Economy
Thinking about AI as just a list of services misses the point. AI isn’t something that works by itself. It’s always part of a product, built on top of some technical foundation, and tied into how the whole business runs. That’s why our Raleigh AI teams structure their work around these three main areas.
Core AI Services — the intelligence itself: This is about creating the intelligence your customers will use. It involves picking the right AI model, checking how well it performs, setting up systems like RAG (Retrieval Augmented Generation), fine-tuning models, and getting AI agents to work together smoothly for complicated tasks.
- AI Development & Integration — Here, we build things like special language models, systems to understand text, computer vision for images, tools that predict things, and smart ways to process documents. We also set up the underlying systems for RAG, built tools to test how well our AI works, and wrote documentation that keeps AI risks in mind.
- Agentive AI Apps — These are smart AI assistants that can handle tasks on their own, like directing customer claims, booking appointments, reviewing documents, pulling together research, or managing approval processes. We also make sure there’s always a way for people to step in, that the AI uses tools in an organized way, and that everything is recorded carefully for auditing.
Product Surfaces Where AI Lives — how users actually meet the model: AI usually isn’t a product all by itself. Instead, it’s built into an app, a website, a software service you use online (SaaS), or a customer relationship management system. Creating the part that users see is just as important as creating the AI model itself.
- Web Development — This means building websites that are smarter with AI, offering things like smart search, personalized content, understanding documents, and chat features that can handle a lot of users.
- Mobile App Development — We also create mobile apps that use machine learning directly on your phone, include features powered by large language models, and give users a personalized experience, all ready for the App Store and Google Play.
- SaaS Product Development — We develop online software services (SaaS) where AI is at the core, running the whole product. These come with built-in subscription management, user roles, and ways to see how everything is performing.
- Custom CRM Development — This involves building custom CRM systems that use AI to score potential leads, predict when customers might leave, summarize conversations, and automate sales processes.
- E-commerce Development — For online stores, we create platforms that use AI for product recommendations, predicting how much demand there will be, preventing fraud, and allowing customers to search by just talking naturally.
Foundations — what AI runs on: Getting AI to work in the real world isn’t just about having an AI model you can access with code. Instead, it needs a whole setup of underlying technology that helps manage costs, lets you see what’s happening, and has a design that makes the AI’s choices clear.
- Cloud Infrastructure / DevOps — This includes managing machine learning operations on cloud platforms like AWS and Azure. It covers tracking different versions of models, automatically retraining them, spotting when models start to perform differently, keeping detailed records, and hosting everything in a way that meets HIPAA and SOC 2 security standards.
- UI/UX Design — This means designing interfaces where users can easily understand how the AI makes its choices. We show things like how confident the AI is, where its information comes from, and clear explanations, all part of building user trust over time.
AI Builds Already Running in Production
We do not need to fill this section with mockups. Two real AI systems that are already working for users tell the story better.
- PromptBatch. Managing AI Costs for Big Organizations: A web platform for companies that use thousands of AI prompts every day across departments. It helps track costs for each API call, shows real-time usage, controls who can access what, optimizes batch processing, and keeps logs that meet business standards. What it offers for Raleigh: a system to manage AI costs that organizations like NC State research programs Dukes clinical AI projects, startups at Centennial Campus, and top teams at Apple need. It’s the infrastructure that turns AI from a test project into a reliable system.
- Rep360 AI. AI Agents in Real Sales Workflows: An AI tool that works inside GoHighLevel CRM and automates sales conversations from start to finish. It qualifies leads through language books, appointments, and passes conversations to humans when needed, and feeds clean data back into the CRM. What it offers for Raleigh: AI that actually works with systems. It ensures connections handle retries, is designed to prevent prompt injection, uses structured tools, and provides the insights that let sales teams trust AI with important interactions. This is the approach that AI agents, in healthcare, document review, and operations automation, need from the start.
Work Highlights
Some of our best works from many
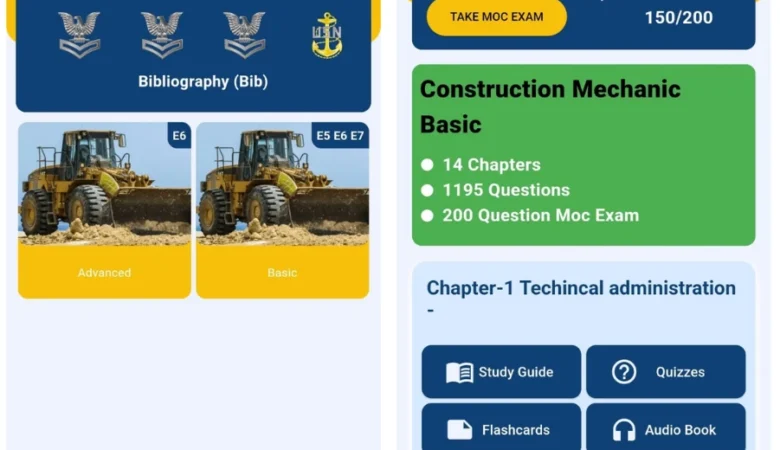
SeaBee – The Best Navy
SeaBee – The Best Navy Exam Study App Built for US Navy Seals Project Overview
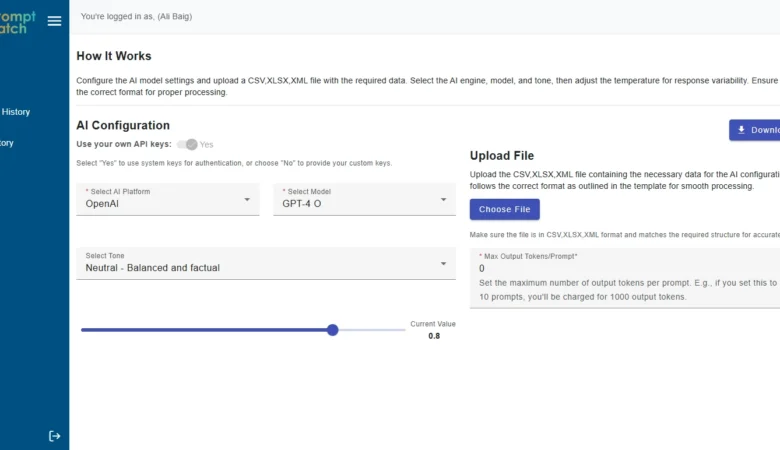
PromptBatch: Save 50% with AI
PromptBatch: The Best AI Batch Prompt Processing Web App | Orbilon Tech Project Overview PromptBatch
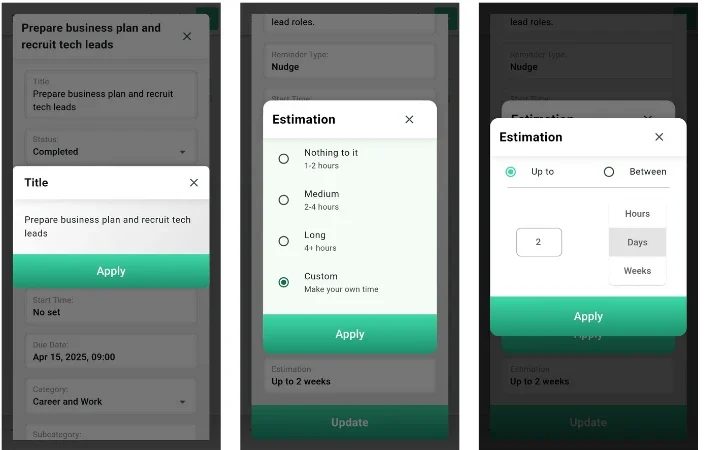
Spheres – The Revolutionary AI
Spheres – The Best AI Life Manager Mobile App That Actually Knows You Project Overview
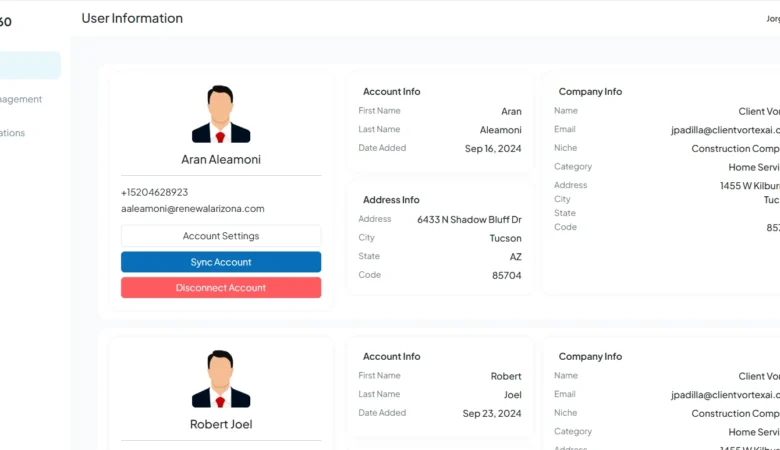
Rep360 AI – AI Bot
Rep360 AI – AI Bot Integration for GHL Workflows That Automates Sales Conversations Project Overview
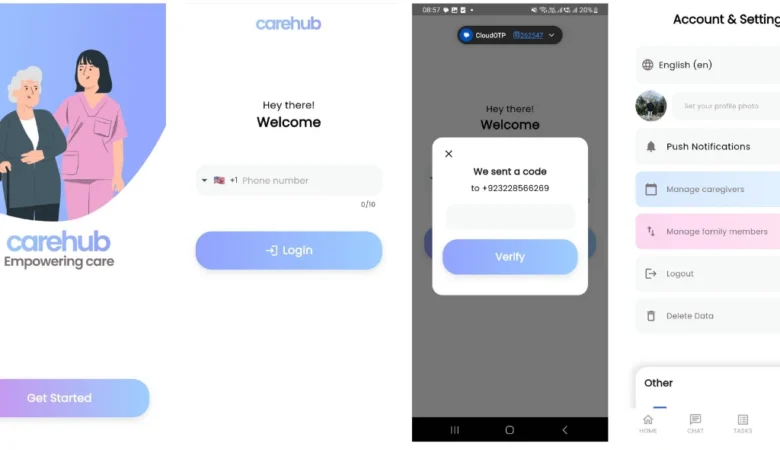
CareHub – Powerful Caregiver Communication
CareHub – Caregiver Communication App With Auto Translation CareHub App – Empowering Care CareHub is
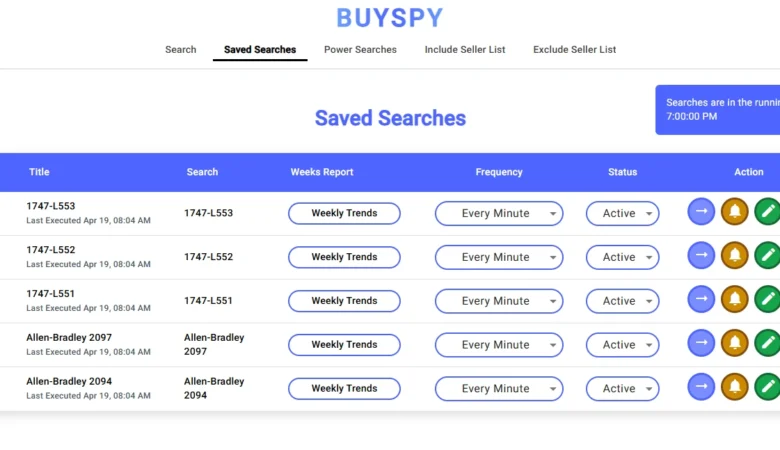
BuySpy – Ultimate Real-Time eBay
BuySpy — A Powerful Real-Time eBay Search Alerts App for Web & Mobile BuySpy is
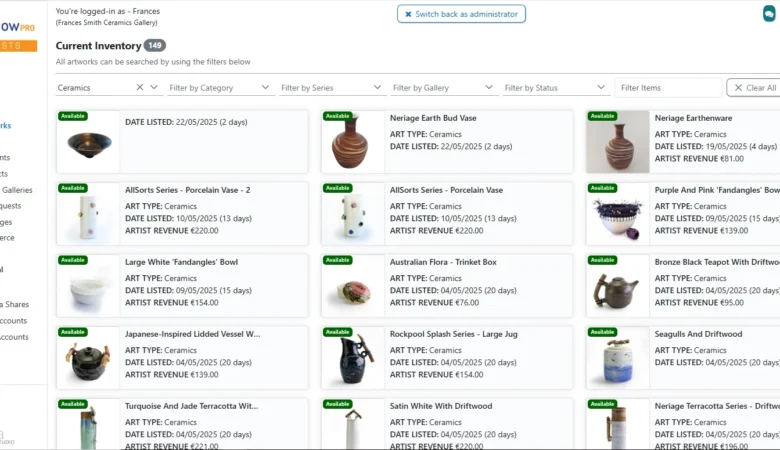
ArtFlow Pro — The Art
ArtFlow Pro — Full-Stack Art Gallery SaaS Platform for Artists & Galleries ArtFlow Pro –
Want to Hire Us?
Are you ready to turn your ideas into a reality? Hire Orbilon Technologies today and start working right away with qualified resources. We will take care of everything from design, development, security, quality assurance, and deployment. We are just a click away.