

Claude Fable 5 and Mythos 5: Anthropic's Most Powerful AI Models Yet
Introduction
The model Anthropic, which was too afraid to release, is now in your hands.
On June 9, 2026, Anthropic did something it had never done before. It handed the public a model from its top-secret “Mythos” tier, the class of models that, until now, only cyber-defense partners and a handful of biology researchers were allowed to touch. The public-safe version is called Claude Fable 5, and it does not sit in the Opus family. It sits above it.
This launch comes with a remarkable backstory. Just days earlier, Anthropic had publicly warned that frontier AI is becoming dangerously capable, urging major labs to establish a coordinated “brake pedal” on development. Then it released its most powerful generally available model ever. Claude Fable 5 wraps the same underlying capability as the restricted Claude Mythos 5, but with an aggressive new safeguard layer that makes it safe enough for anyone to use.
If you build products, ship code, or run AI in production, this is the launch that matters most in 2026. Here is everything you need to know about Claude Fable 5: the benchmarks, the pricing, the safety catch, and whether it is worth the premium.
The Shift: Before and After Claude Fable 5
Before Claude Fable 5:
- Mythos-class power is locked to a few vetted partners.
- Hardest coding tasks capped at Opus 4.8 levels (69.2% SWE-Bench Pro).
- Complex 50-million-line migrations took weeks of engineering time.
- Frontier capability was something you read about, not used.
After Claude Fable 5:
- Mythos-class power available to anyone via API and Enterprise plans.
- Agentic coding jumps to 80.3% SWE-Bench Pro, a 20-point lead over rivals.
- A 50-million-line codebase migration finished in a single day.
- The most capable model ever released is in your hands today.
This is not incremental. It is the biggest single jump in publicly available AI capability in 2026.
What Claude Fable 5 Actually Is?
For most of 2026, Anthropic’s most powerful technology was locked away. In April, the company unveiled Mythos, a model that excels at finding security flaws in software, and deliberately limited its release through a cybersecurity initiative called Project Glasswing. It went to only a small group of vetted cyber defenders and critical infrastructure providers because Anthropic feared its capabilities could cause serious damage in the wrong hands.
Claude Fable 5 changes that. It is the first publicly available Mythos-class model, a tier that sits above the Opus line in capability. Anthropic made this broad release possible by developing new safeguards strong enough to reliably prevent misuse.
The key relationship to understand:
- Claude Fable 5 is the public version with safeguards on. Available to everyone via the Claude API and Enterprise plans.
- Claude Mythos 5 is the same underlying model with safeguards lifted in restricted domains. Available only to vetted Project Glasswing partners and approved biology researchers.
They share the same weights. The difference is the safety layer. For most ordinary enterprise and developer tasks, Anthropic says Fable 5 performs effectively the same as Mythos 5. This is the model we previewed in our earlier coverage of the Claude Mythos preview and Project Glasswing, now finally available to the public.
The Benchmarks: Why This Is a Jolt, Not an Inch?
If you have spent the last year watching models improve half a point at a time, Claude Fable 5 is a shock. It does not inch forward. It leaps.
a. Claude Fable 5 Key Benchmark Scores
| Benchmark | Fable 5 | Opus 4.8 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-Bench Pro (agentic coding) | 80.3% | 69.2% | 58.6% | 54.2% |
| SWE-Bench Verified | 95.0% | 87.6% | ~80% | – |
| Terminal-Bench 2.1 | 88.0% | – | – | – |
| FrontierCode Diamond | 29.3% | 13.4% | – | – |
In plain language for mobile readers:
SWE-Bench Pro: Fable 5 scores 80.3%, an 11-point lead over Opus 4.8 (69.2%) and more than 20 points ahead of GPT-5.5 (58.6%) and Gemini 3.1 Pro (54.2%). On agentic coding, nothing else comes close.
SWE-Bench Verified: 95.0%, the highest publicly available score ever recorded.
FrontierCode Diamond: 29.3% versus 13.4% for Opus 4.8, a 2.2x lead on the hardest coding tasks.
The pattern across every benchmark is consistent: the longer and more complex the task, the larger Fable 5’s lead. It reportedly finished a migration in a 50-million-line codebase in a single day. This continues the trajectory we tracked in our Claude Opus 4.8 deep dive, except Fable 5 is a full tier above it.
b. Visual: SWE-Bench Pro Comparison
Here is the agentic coding gap visualized, so the lead is easy to see at a glance:
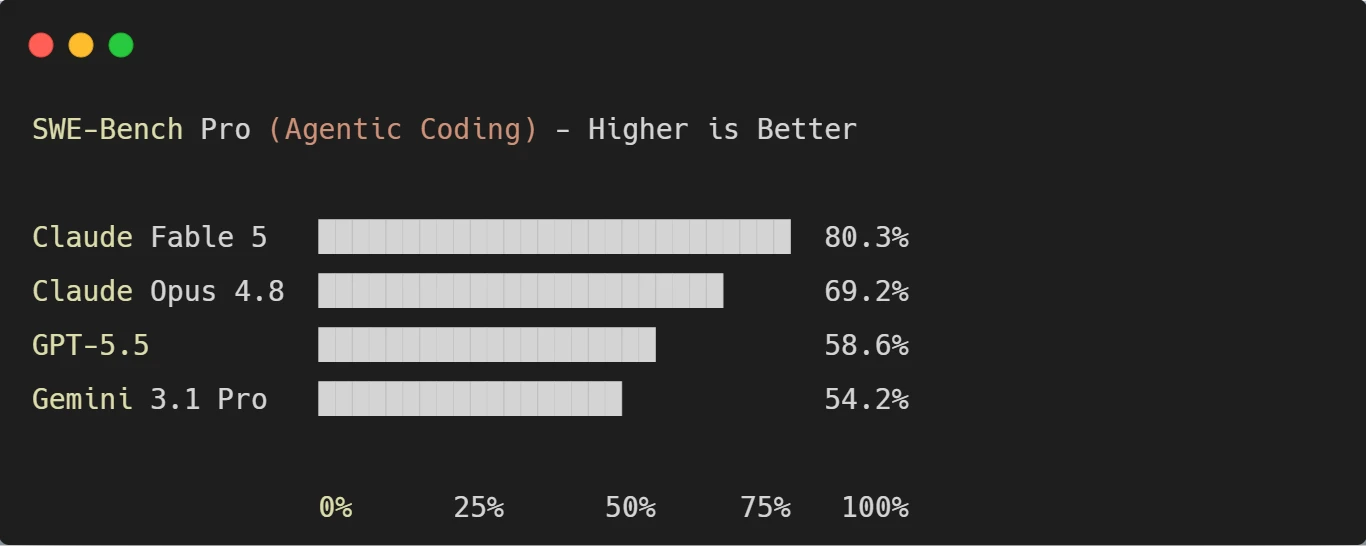
The gap is not subtle. Fable 5 leads the next-best model by 11 points and rivals by more than 20. On the hardest coding tasks, nothing publicly available comes close.
One important note on the numbers: some of the most eye-catching benchmark figures, particularly in cybersecurity and biology, belong to the restricted Mythos 5, not the public Fable 5. In those high-risk domains, Fable 5 silently falls back to Opus 4.8. Treat starred benchmarks as the ceiling of the restricted tier, not what you will actually get.
The Safety Catch You Need to Understand
This is the most important part of the Claude Fable 5 story, and it changes how you should think about deploying it.
Fable 5 ships with the most aggressive safety scaffolding Anthropic has ever put on a general release. When a request touches certain high-risk areas, including cybersecurity, biology, chemistry, and model distillation, the model automatically reroutes the response to Claude Opus 4.8 instead. Users are notified when this happens.
What this means in practice:
- You get Mythos-class performance in normal domains: software engineering, knowledge work, vision, scientific research, document reasoning, and professional workflows.
- You get Opus 4.8 performance in safeguarded domains. If your work involves cybersecurity, biology, or chemistry, Fable 5 will fall back, and you are effectively paying a premium price for Opus-level output.
Anthropic tuned these safeguards conservatively, meaning they sometimes catch harmless requests. The company says they trigger, on average, in less than 5% of sessions. But for teams working in security or life sciences, that 5% could include exactly the work you need most.
This safety-first design philosophy is why many enterprises choose Anthropic, a topic we explored in depth in our breakdown of why businesses use Claude AI.
Pricing: Premium Performance, Premium Cost
Claude Fable 5 is not cheap. Here is the cost picture.
Claude Fable 5 Pricing:
| Type | Input (per 1M) | Output (per 1M) |
|---|---|---|
| Standard | $10 | $50 |
| Batch | $5 | $25 |
In simple terms:
Standard pricing is $10 per million input tokens and $50 per million output tokens, exactly double Claude Opus 4.8.
Batch pricing halves that to $5 input and $25 output for non-real-time work.
Prompt caching offers up to a 90% discount on input, which matters for long-running agentic tasks that reuse context.
There is a free window worth knowing about. Through June 22, 2026, Fable 5 is included in Pro, Max, Team, and seat-based Enterprise plans at no extra cost. On June 23, Anthropic will pull it from those plans, requiring usage credits going forward, with stated plans to restore it as a standard feature when capacity allows.
The practical pricing takeaway: Fable 5 is worth the premium for hard, complex, long-horizon tasks where its lead is largest. For routine work, Opus 4.8 at half the price often makes more economic sense. One honest limitation: Fable 5 currently has mandatory 30-day data retention with no zero-retention option, which may matter for privacy-sensitive deployments.
Where Claude Fable 5 Makes Sense?
Given the premium price and the safeguard fallback, Fable 5 is not the right default for every task. Here is where it genuinely shines.
Best Use Cases for Fable 5:
- Complex, long-running coding tasks. Large refactors, codebase-wide migrations, and multi-step engineering work, where the 80.3% SWE-Bench Pro lead translates to real-time savings.
- Hard knowledge work. Research synthesis, complex analysis, and professional workflows where its GDPval-AA lead (1932 Elo) shows up.
- Long-horizon agentic work. Tasks that run for extended periods, where Fable 5 sustains performance that previous models could not.
- Document and vision reasoning. Complex document processing and visual analysis, where its capabilities exceed Opus 4.8.
Where to Stick With Opus 4.8:
- Routine coding and everyday tasks, where Opus 4.8 at half the price delivers more than enough capability.
- Cybersecurity, biology, and chemistry work where Fable 5 falls back to Opus 4.8 anyway, so you gain nothing for the premium.
- High-volume, cost-sensitive workloads where doubling your token cost is not justified by the task difficulty.
This decision-making mirrors the broader multi-model strategy we covered in our Claude Opus 4.8 vs GPT-5.5 vs Gemini comparison: route hard tasks to the most capable model, and routine work to the cost-efficient one.
Where You Can Use It Right Now?
Claude Fable 5 launched with immediate broad availability across major platforms.
- Claude API: Available now with model ID claude-fable-5.
- Amazon Bedrock: Live on AWS, with the Claude Platform on AWS support.
- Subscription plans: Free access through June 22 on Pro, Max, Team, and Enterprise, then usage-credit-based.
- Context window: 1 million input tokens, 128K output tokens.
- Modalities: Text and vision input, text output, with extended thinking always on.
This day-one multi-platform availability is part of why Anthropic has become the enterprise default, and it reflects the same any-cloud strategy that makes Claude the only frontier model on AWS, Google Cloud, and Microsoft Foundry at the same time.
The Bigger Picture: A New Way to Ship Dangerous AI
Step back, and the Claude Fable 5 launch signals something important about how frontier AI will reach the market.
Anthropic did not release all of Mythos 5’s capabilities to everyone. It also did not simply refuse to release them. Instead, it found a middle path: take the powerful underlying model, wrap it in safeguards that block the genuinely dangerous use cases, and release that public-safe version broadly while keeping the unrestricted version locked to vetted partners.
This is a template for the industry. As models grow more capable, the question of how to deploy dual-use technology safely becomes urgent. Anthropic’s answer with Fable 5 and Mythos 5, the same model split into a safeguarded public tier and an unrestricted tier, may become the standard approach across all major AI labs.
The timing also matters commercially. This launch comes as Anthropic prepares for a potentially massive IPO, alongside OpenAI and SpaceX. Releasing its most powerful model publicly, while demonstrating responsible safeguards, positions the company well for both investors and regulators. It is a careful balance, and one that every business deploying frontier AI should understand, because it reflects exactly the kind of disciplined approach that separates successful AI adoption from the failures we documented in “ Why AI projects fail.
The Gap: Teams Using Fable 5 vs Everyone Else
Here is the uncomfortable truth about where AI-powered development is heading in 2026.
Teams NOT using Fable 5 for hard tasks:
- Capped at Opus-level performance on their most complex work.
- Spending weeks on migrations that could finish in a day.
- Watching competitors ship faster on the hardest problems.
- Paying engineers to do work that the model could sustain autonomously.
Teams using Fable 5 strategically:
- Solving their hardest coding problems at 80.3% SWE-Bench Pro.
- Compressing multi-week migrations into single days.
- Routing routine work to cheaper Opus 4.8, premium work to Fable 5.
- Freeing senior engineers for architecture and judgment, not mechanical work.
The gap is not about using Fable 5 for everything. It is about knowing exactly when Mythos-class capability is worth the premium, and deploying it precisely where it creates the largest advantage. The teams that master this routing win on speed without overpaying.
The ROI Math: When the Premium Pays Off
Let us be concrete about when Fable 5’s double pricing makes business sense.
A complex migration scenario:
- Manual approach: 3 senior engineers x 3 weeks = ~360 engineer-hours.
- At a $100/hour loaded cost, = $36,000 in labor.
- Fable 5 approach: completes in 1-2 days, with engineer review.
- Even at a premium token cost (a few hundred dollars), the savings are dramatic.
The decision rule: For tasks where Fable 5’s lead translates to days or weeks of saved engineering time, the premium pays for itself many times over. For routine work where Opus 4.8 is “good enough,” stick with the cheaper model. The art is in the routing, not in defaulting everything to the most powerful model.
This disciplined, cost-aware deployment is exactly what separates teams that capture real ROI from those that overspend, a pattern we documented across every category in our analysis of why AI projects fail.
Conclusion: The Most Powerful Model You Can Actually Use
Claude Fable 5 is a genuine milestone. For the first time, Anthropic has made a Mythos-class model, a full tier above Opus, available to the public. It posts the highest publicly available benchmark scores ever recorded, leads agentic coding by more than 20 points over its nearest competitor, and can sustain complex work that no previous model could handle.
The catch is real: premium pricing at double Opus 4.8, a safeguard layer that reroutes high-risk queries, and mandatory data retention. For routine work, Opus 4.8 remains the smarter economic choice. But for the hardest, longest, most complex tasks, where capability matters more than cost, Fable 5 is now the most powerful tool available to anyone.
The model Anthropic, which was too afraid to release, is now in your hands, carefully wrapped in safeguards, but more capable than anything you could use before. The question is no longer whether you can access Frontier AI. It is whether your hardest problems are worth the premium to solve them faster than ever before. Test it on your own workloads during the free window, measure the difference, and decide where Mythos-class capability earns its price.
Build It With Orbilon Technologies
Orbilon Technologies turns frontier AI into production systems that actually ship. We build on the latest models, like Claude Fable 5, Claude Opus 4.8, and GPT-5.5, then we design agentic coding workflows, multi-model routing, custom AI agents, and full enterprise AI blueprints across AWS Bedrock, Google Vertex AI, and Microsoft Foundry.
Since 2015, we’ve delivered 100+ projects for clients across the US, Europe, and the Middle East. Everything from SaaS startups to financial services teams, and even healthcare platforms, plus enterprise operations groups that need it to work day after day. We’re a top-rated AI development partner with verified client feedback on Clutch, GoodFirms, Google, and Upwork, and people mention transparency, fair pricing, and that post-launch support is handled, not ignored.
Interested in building with Claude Fable 5 and other frontier models? Grab a free consultation. We’ll go over your toughest workloads, and we’ll point out, plainly, where Mythos class capability earns its premium, and where it just doesn’t.
- Email: support@orbilontech.com
Want to Hire Us?
Are you ready to turn your ideas into a reality? Hire Orbilon Technologies today and start working right away with qualified resources. We will take care of everything from design, development, security, quality assurance, and deployment. We are just a click away.

