
AI Development in Boulder - Colorado | Orbilon Tech
A City Where Google and IonQ Build Quantum Computers, and AI Conversations Start at the Research Frontier
AI development in Boulder operates next door to some of the most advanced computing research on the planet. Google recently tapped a CU Boulder physicist to lead a new quantum-computing hardware team in the city, and IonQ opened a quantum computing R&D lab here, drawn by Boulder’s standing as a recognized global hub for atomic, molecular, and optical physics.
CU Boulder runs a Quantum Intelligence Lab focused on the intersection of quantum computing and AI, and a Colorado AI Lab advancing machine learning, computer vision, robotics, and human-centered autonomy. When the surrounding research community is pushing the frontier of computation itself, the local definition of serious AI rises with it.
That research density shapes a market that asks sharp questions before it signs anything. Boulder pairs that academic depth with one of the most efficient startup engines in the country. CU Boulder spins out dozens of companies a year, many touching AI, sensing, or autonomy, and the Techstars pipeline keeps founders flowing into the market.
The roster of buyers here includes deep-tech ventures, climate and bioscience startups, aerospace and autonomy companies, and the wellness and consumer brands that define the city. They tend to understand evaluation methodology, model governance, and the difference between a slick demo and a production system, because many of them came out of the same research labs now defining trustworthy AI.
For organizations seeking the best AI development company in Boulder, one capable of shipping AI that survives a research-grade technical review, scales with a venture-backed startup, and operates reliably in production rather than in a notebook, Orbilon Technologies delivers custom AI solutions in Boulder with full lifecycle ownership.
That covers production LLM systems, retrieval-augmented generation pipelines, machine learning models, computer vision, autonomous AI agents, and the governance, observability, and cost-control infrastructure that turns research-grade ideas into dependable production capability.
What Founders Trained in Research Labs Expect Before They Trust an AI System?
The distinctive feature of the Boulder AI market is a buyer base shaped by the research frontier. Founders here often hold advanced degrees, came out of CU Boulder or a federal lab, or built their company on a research insight. They evaluate AI the way a scientist evaluates a claim: with skepticism, a demand for evidence, and zero patience for hand-waving. AI development in Boulder, CO, has to meet that standard from the first conversation.
These are the qualities that earn trust in this market.
- Evidence beats assertion every time. A research-trained buyer wants to see measured performance, documented evaluation methodology, and honest accounting of where a model fails. Production AI here ships with hallucination rates measured on representative data, evaluation harnesses built around the actual use case, and the kind of empirical rigor a peer reviewer would accept.
- Reproducibility is treated as a scientific requirement. A system that cannot reproduce its results is not trustworthy to people who reproduce experiments for a living. Production builds lock model versions, freezes embeddings, versions the retrieval store, and logs every decision so behavior is auditable and repeatable. Hire AI engineers in Boulder who wave away reproducibility, and a research-minded founder loses confidence immediately.
- Scalability is part of the architecture conversation. A venture-backed Boulder startup expects its AI to scale from a seed-stage prototype to a funded product without a ground-up rebuild. The architecture has to anticipate growth in data volume, user load, and model complexity from the first sprint.
- Human-centered design matters here. Boulder’s research community emphasizes trustworthy AI that works alongside people, with transparency, explainability, and appropriate human oversight. Systems that behave like inscrutable black boxes get a cold reception in a market that studies human-AI collaboration academically.
- Total cost of ownership is a real calculation. Founders watching a burn rate think hard about inference cost at scale, model-routing economics, and the operational burden of keeping AI current. Vendors who price honestly for the full lifecycle, not just the build, earn a long-term relationship.
The teams that succeed in Boulder treat a research-literate audience as the ideal client for AI done with genuine rigor. The same scrutiny that exposes shallow work makes real engineering and honest evaluation visible and valued across a tightly connected community.
Picking the Architecture: Retrieval, Agents, Vision, and Fine-Tuning
The structure of an AI system, not the model powering it, is usually what decides success. Generative AI development Boulder projects tend to fail on architectural mismatch rather than model choice. Several foundational patterns recur in serious Boulder work, and the strongest systems combine them with intent.
- Retrieval-grounded answering. When the AI must respond from an organization’s own research, documentation, technical knowledge, or proprietary data, retrieval-augmented generation is the foundation. Vector stores (Pinecone, Weaviate, Qdrant, Chroma, or pgvector inside Postgres), hybrid search blending dense vectors with keyword retrieval, reranking through Cohere or cross-encoder models, document-aware chunking, and citation trails the user can audit. RAG development Boulder for technical knowledge bases and research-driven products is a frequent starting point.
- Computer vision and perception. When the problem involves images, video, sensor data, or autonomy, vision models anchor the system. Computer vision development in Boulder draws on the city’s strength in robotics and autonomy research, with robust training pipelines, careful evaluation across conditions, and deployment that holds accuracy in the real world rather than only on a benchmark.
- Tool-using agents. When AI needs to act rather than answer, calling APIs, querying systems, orchestrating multi-step workflows, agentic architecture applies, with structured tool calling, sandboxed execution, authority boundaries the model cannot exceed, human oversight on consequential actions, and complete audit trails on every tool call.
- Fine-tuned and specialty models. When base models cannot reliably produce the terminology or behavior a research or domain use case demands, fine-tuning earns its cost, paired with smaller task-tuned models (Phi, Gemma) for high-volume classification at lower per-call expense. Research teams with curated datasets are the natural users.
- Production systems in Boulder rarely use one pattern alone. A reasoning model anchors the system, retrieval grounds it, vision handles perception, agents execute, and specialty models slot in where each stage benefits. Forcing one pattern onto every problem leads to a rebuild within roughly a year and a half.
Selecting a Model for a Research-Grade, Startup-Speed Market
Model choice shapes cost, latency, governance, and roadmap for years, and Boulder buyers weigh those tradeoffs with unusual sophistication. Machine learning development in Boulder here balances reasoning quality, evaluation results on the actual data, fine-tuning needs, data residency, and the speed a venture-backed timeline demands. There is no universal answer, only the right answer for the problem and the evidence.
- OpenAI (GPT family). A strong pick when broad reasoning quality and ecosystem maturity, including function calling, structured outputs, vision, and reasoning models, accelerate a startup’s path to a working product. Azure OpenAI provides governed deployment when compliance enters the picture.
- Anthropic Claude. A strong pick when long-context reasoning, careful instruction following, and lower hallucination rates matter, which suits research-document analysis, technical summarization, and agentic workflows where a carefully hedged answer beats a confidently wrong one.
- Self-hosted open models (Llama, Mistral, Qwen). The right pick when data sensitivity rules out external APIs, when on-premise deployment is required, when inference volume favors self-hosting economically, or when fine-tuning on proprietary research data delivers compounding gains. Deep-tech and research-driven Boulder teams handling sensitive or unpublished data often default here.
- Specialty and small models. Embeddings (OpenAI, Cohere, Voyage), purpose-built vision models, and small task-tuned models (Phi, Gemma) layered into systems where a flagship model would be overkill or too costly for the constraint, an approach that cost-aware startups appreciate.
The mistake that costs the most is choosing a model from a benchmark headline. The reliable path is benchmarking candidates against your own data, prompts, and evaluation criteria, which we run as part of the engagement rather than as an upsell.
Trustworthy AI in Practice: Governance, Privacy, and Cost Discipline
Boulder’s research community has helped define what trustworthy AI means, and that influence raises governance expectations across the local market. AI development company Boulder buyers expect safety, privacy, and cost handled as engineering disciplines with concrete solutions, not as policy statements written after launch.
- Evaluation and transparency are foundational. Documented evaluation methodology, performance reporting that includes failure modes, model cards documenting training data and limitations, and the kind of transparency a research-literate buyer can actually scrutinize. This is governance modeled on academic rigor.
- Bias and fairness testing run before and after launch. Performance evaluation across relevant subgroups, fairness reporting, documented mitigation where disparities surface, and continuous monitoring once live, reflecting the human-centered AI principles Boulder’s research community emphasizes.
- Prompt-injection defenses are part of the threat model. Systems taking untrusted input face manipulation attempts, met with layered defenses: input filtering, structured-output enforcement, sandboxed tool execution, output validation, and authority boundaries on what the model can invoke.
- Privacy protection runs inline. PII detection and redaction through Microsoft Presidio or custom rule engines, running before context reaches the model and again before output reaches the user, with governed inference endpoints for sensitive research and personal data.
- Cost governance prevents runaway spend. Production AI at scale accumulates real token cost. Our PromptBatch platform handles this layer, enforcing per-user, per-feature, and per-tenant ceilings, routing easy requests to cheaper models, caching duplicate calls, and surfacing anomalies before they reach the invoice, the kind of discipline a burn-rate-conscious startup market expects.
- Observability runs continuously in production. Drift detection, performance monitoring on representative inputs, regression testing as upstream models update, and dashboards that surface quality decay before users notice, the operational rigor that separates a maintained system from an abandoned experiment.
How We Organize AI Work Across Boulder's Research, Startup, and Lifestyle Sectors?
Boulder AI demand clusters into recognizable groups, including deep-tech and research-driven ventures, venture-backed startups, climate and bioscience, autonomy and robotics, and wellness and consumer brands. Rather than a flat service list, here is how the work maps to what each kind of Boulder buyer actually needs.
| Service: | What we build with it | Best fit in Boulder |
|---|---|---|
| AI Development & Integration | Production LLMs, RAG pipelines, machine learning models, computer vision, predictive analytics | Deep-tech and research-driven ventures needing measured, documented AI |
| Agentive AI Apps | Autonomous agents with human-in-the-loop oversight, sandboxed execution, and audit logging | Research synthesis, document review, and workflow automation |
| SaaS Product Development | Multi-tenant AI-native platforms, subscription billing, and observability | Venture-backed startups scaling through funding rounds |
| Web Development | AI-enhanced platforms with intelligent search, personalization, and chat interfaces | Product surfaces that put models in front of users |
| Mobile App Development | On-device ML via Core ML and TensorFlow Lite, computer vision, AI personalization | Consumer, wellness, and autonomy apps on iOS and Android |
| Custom CRM Development | AI lead scoring, churn prediction, pipeline forecasting, conversation intelligence | Startup and B2B sales operations |
| E-commerce Development | AI product discovery, demand forecasting, fraud prevention | Natural products, wellness, and consumer brands |
| Cloud Infrastructure / DevOps | MLOps with model versioning, retraining, drift detection, SOC 2, and HIPAA-aware hosting | The monitored foundation research-grade AI requires |
| UI/UX Design | Transparent AI interfaces with confidence scores, citation trails, and explainability. | Products in a market that studies human-AI collaboration |
Proof in Production: Two Systems Boulder Builders Can Inspect
Research-trained buyers don’t really take the vendor’s word for it, you know, so instead of hand-wavyreal-time claims, here are two things that are already live with real customers, and kind of taken apart the way an engineer would, like, not in a glossy way.
PromptBatch, view the build:
- What it is: a SaaS service for orgs running thousands of AI prompts every day across several teams.
- Under the hood: per-call cost metering, role-based usage dashboards,calendar-awareauthority-boundautonomy-stylehand-wavy real-timed access controls, batch processing tuning, semantic caching to chop duplicate inference, and logs you can actually audit later.
- The Boulder fit: this is basically the governance + cost layer that every deep-tech effort, and every “we’re scaling AI now” team, eventually needs. It turns the whole AI prototype situation into a system where finance, compliance, and engineering leadership can sign off, without the usual drama.
Rep360 AI, view the build:
- What it is: an AI agent that sits inside live GoHighLevel CRM automations, and it runs the sales conversations end to end.
- Under the hood: natural language lead screening, calendar aware appointment scheduling, fallback to humans when the case is complicated, and structured information written back to the CRM in a clean way.
- The Boulder fit: the agent engineering part, plus webhook reliability, idempotent retries (so you don’t get double actions), prompt injection resistance, structured tool calling, and authority bounded execution, is pretty much what research workflow agents and autonomy style apps are asking for.
Work Highlights
A selection of our most notable projects across a diverse range of industries.
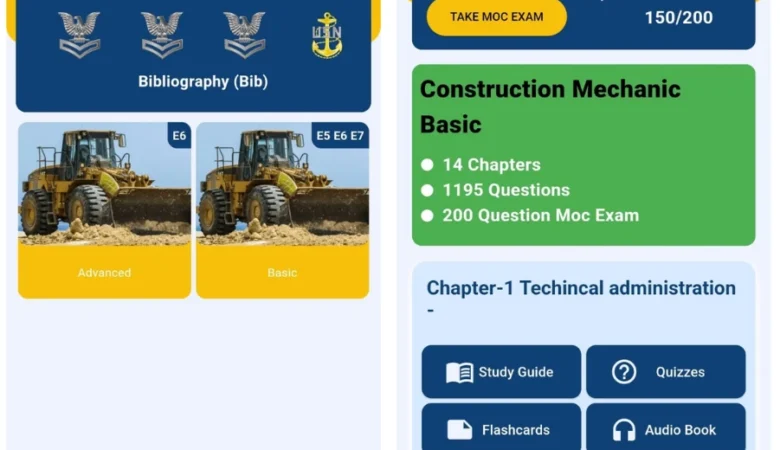
SeaBee – The Best Navy
SeaBee – The Best Navy Exam Study App Built for US Navy Seals Project Overview SeaBee is a free, comprehensive
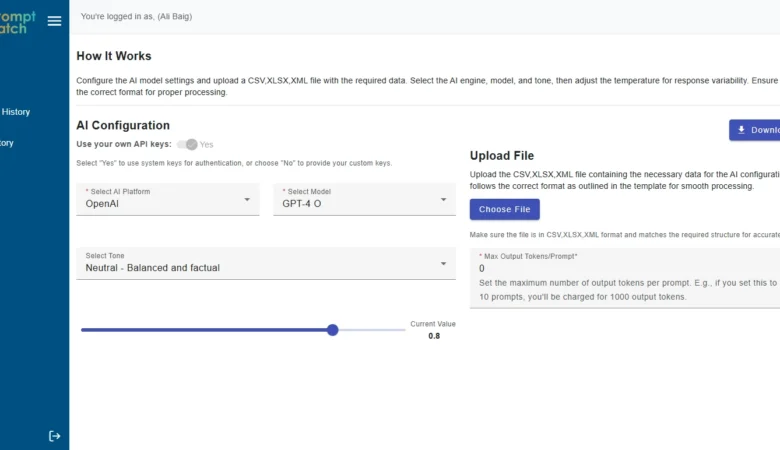
PromptBatch: Save 50% with AI
PromptBatch: The Best AI Batch Prompt Processing Web App | Orbilon Tech Project Overview PromptBatch Portal is a powerful AI
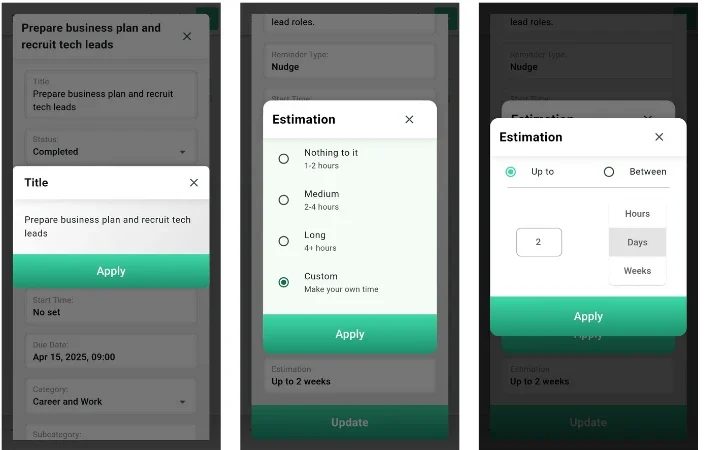
Spheres – The Revolutionary AI
Spheres – The Best AI Life Manager Mobile App That Actually Knows You Project Overview Spheres – Life Simplified is
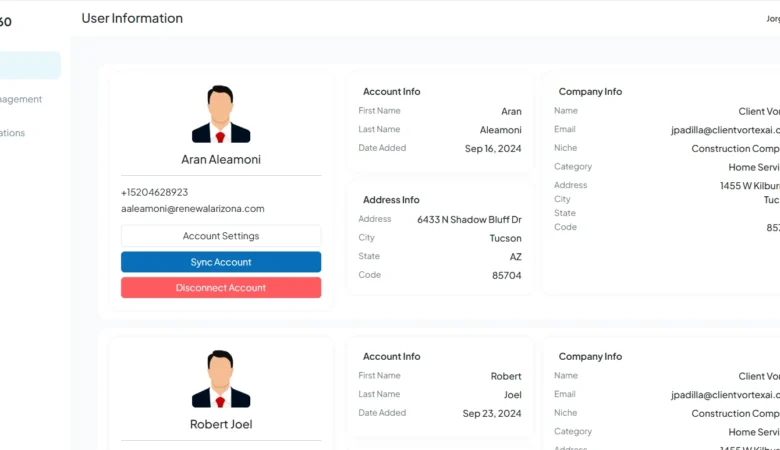
Rep360 AI – AI Bot
Rep360 AI – AI Bot Integration for GHL Workflows That Automates Sales Conversations Project Overview Rep360 AI is a fully
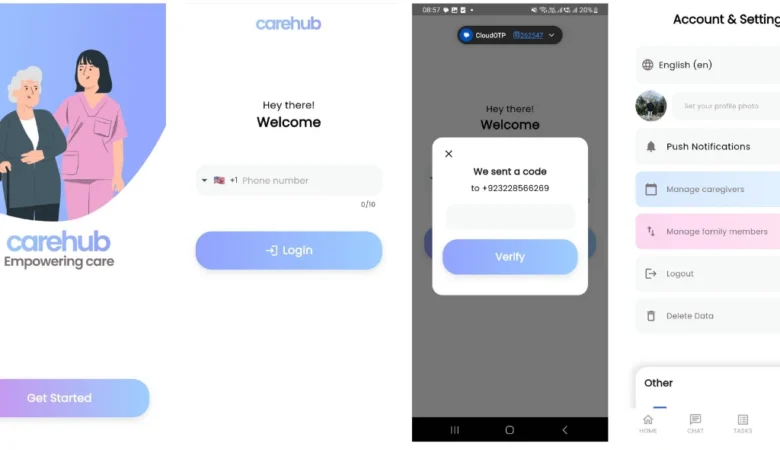
CareHub – Powerful Caregiver Communication
CareHub – Caregiver Communication App With Auto Translation CareHub App – Empowering Care CareHub is a powerful caregiver communication app
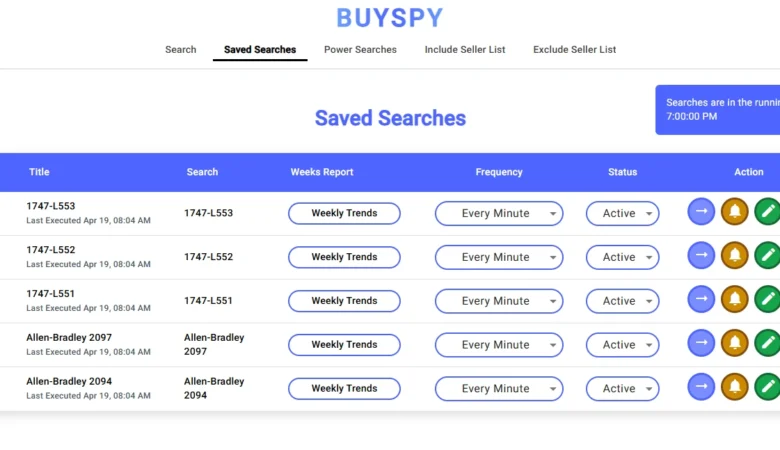
BuySpy – Ultimate Real-Time eBay
BuySpy — A Powerful Real-Time eBay Search Alerts App for Web & Mobile BuySpy is a real-time eBay search alerts
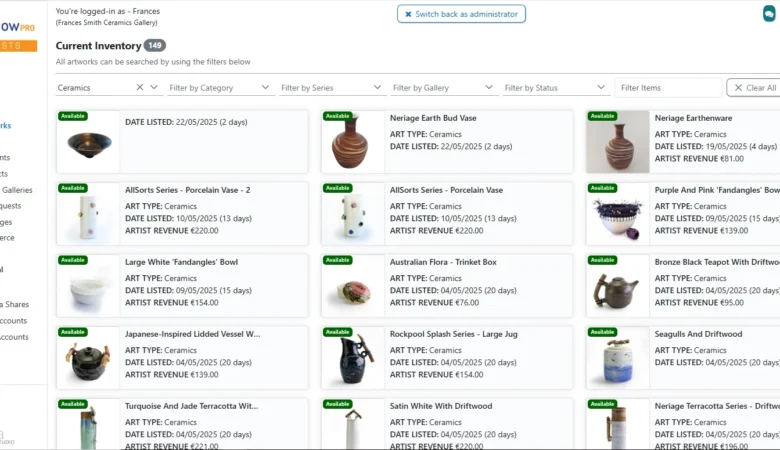
ArtFlow Pro — The Art
ArtFlow Pro — Full-Stack Art Gallery SaaS Platform for Artists & Galleries ArtFlow Pro – Streamline the Artwork Sales ArtFlow
Verified Clutch Reviews From Clients We've Worked With
The following testimonials reflect the experiences of our valued clients:
Want to Hire Us?
Are you ready to turn your ideas into a reality? Hire Orbilon Technologies today and start working right away with qualified resources. We will take care of everything from design, development, security, quality assurance, and deployment. We are just a click away.