

Why Lambda and Claude AI Stack Is Winning in 2026 — And Why Everything Else Is Losing?
Introduction
Here is the uncomfortable truth that most engineering teams running AI workloads haven’t fully internalized yet:
Lambda and Claude AI stack handles 90% of real-world AI use cases better, cheaper, and faster than a dedicated server setup — and most teams are still over-engineering their infrastructure by default.
The use case is specific: workloads with idle periods between traffic bursts that can tolerate cold starts — a document processing service that runs periodically, an internal tool that gets sporadic use, a prototype that needs to stay live without burning budget. That description fits the majority of production AI applications built today — customer support bots, document processing pipelines, content generation APIs, compliance monitoring workflows, and internal knowledge assistants.
Enterprise adoption is accelerating: finance, healthcare, media, and IoT companies now run entire pipelines on serverless due to lower operational burden and predictable scaling. The teams that haven’t made this shift yet are paying for always-on infrastructure that sits idle 70–80% of the time — and calling it a production AI system.
This post covers exactly why the Lambda and Claude AI stack is the dominant architecture for AI workloads in 2026, when it makes sense, when it doesn’t, and how to build it correctly with real production code.
What the Lambda + Claude Architecture Actually Looks Like?
In 2026, serverless isn’t just “Lambda + API Gateway” anymore — it’s the default fabric for modern cloud-native applications. The Lambda and Claude AI stack is a specific pattern within that fabric, designed for AI-first applications that need intelligent processing on demand without the overhead of managing inference servers.
The architecture has three core layers:
- Layer 1 — API Gateway + Lambda (Request handling): Every request hits API Gateway, which routes it to a Lambda function. Lambda validates the input, applies business logic, and prepares the payload for Claude. Lambda charges by the millisecond — billing is in 1-millisecond increments, one of the most granular compute billing models available. When nothing’s happening, you pay nothing.
- Layer 2 — Amazon Bedrock + Claude (Intelligence layer): Amazon Bedrock serves as the intelligence layer, providing access to state-of-the-art foundation models through a consistent API — handling intent recognition, entity extraction, natural language generation, decision-making, and coordination of tool use to interact with external systems. Claude is accessed through Bedrock — no model management, no GPU provisioning, no inference server to maintain.
- Layer 3 — DynamoDB + S3 (State and storage):
State management is handled through Amazon DynamoDB, which provides persistent storage for conversation context even if there are interruptions or system restarts. S3 handles document storage for any file-based AI workflows.
This stack auto-scales from zero to millions of requests with zero infrastructure configuration. When traffic stops, costs drop to zero. When traffic spikes, Lambda scales horizontally in milliseconds.
Why 90% of AI Workloads Don't Need a Dedicated Server?
The claim that 90% of AI workloads don’t need a dedicated server is backed by solid data.
Lambda’s serverless design is especially well-suited for machine learning tasks because it removes the hassle of setting up and managing servers, scales automatically based on demand, and charges you only for what you use. This makes it a great fit for ML inference, where you handle requests as they come or deal with spikes in traffic.
There are cases where dedicated servers still make more sense, about 10% of workloads. For example, if you’re running inference constantly at high volume, it’s cheaper to have reserved capacity than to pay per use. If your task requires extremely low latency, the delays from cold starts and network hops in serverless can be a problem, so dedicated endpoints or edge deployments are better. Also, if you need custom GPU tuning, serverless options usually don’t give you that control.
But for most other use cases—like document processing, support agents, content creation APIs, internal knowledge tools, or compliance checks—the Lambda and Claude AI setup is more cost-effective and simpler to manage than dedicated servers.
The cost difference is notable. For many development and low-traffic apps, Lambda stays within the free tier. Even at a production level—say 4 million calls per month with 512MB memory running for 150ms each—Lambda’s monthly cost is only a fraction of what a dedicated EC2 instance would cost, especially one that sits idle much of the time.
The Real Cost Advantage: Lambda vs Dedicated Server for AI Workloads
| Workload Pattern | Lambda + Claude | Dedicated Server (g4dn.xlarge) | Monthly Saving |
|---|---|---|---|
| 10K requests/month, 2s avg | ~$5–15/month | $526/month (always-on) | $510+ |
| 100K requests/month, 2s avg | ~$50–80/month | $526/month | $450+ |
| 500K requests/month, 2s avg | ~$200–350/month | $1,052/month (2 instances) | $700+ |
| 1M+ requests/month, 2s avg | Evaluate hybrid | Dedicated may be cheaper | Case by case |
Cold Starts: The Most Overstated Problem in Serverless AI
The number one objection to Lambda for AI workloads is cold starts. Cloud providers now offer “provisioned concurrency” and “always-warm execution pools,” lowering cold starts by 60–80% for latency-sensitive apps.
For Claude API calls specifically, the cold start overhead is irrelevant in practice. A Lambda cold start adds 200–500ms of initialization time. Claude’s API response time ranges from 500ms to 3–5 seconds, depending on prompt complexity and output length. The cold start represents 5–10% of total response time — not a meaningful user experience difference.
Provisioned Concurrency eliminates cold starts by keeping execution environments pre-initialized. For latency-sensitive production endpoints — customer-facing chatbots, real-time document analysis, voice interfaces — enable Provisioned Concurrency on your Lambda function, and cold starts become a non-issue entirely.
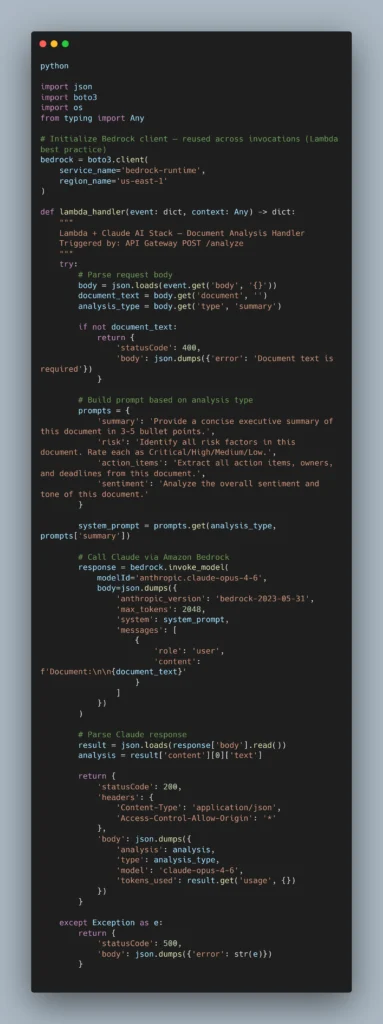
Production Architecture: Lambda + Claude AI Stack Implementation
Built on a fully serverless architecture, the AWS AI Stack utilizes services like AWS Lambda, API Gateway, DynamoDB, and EventBridge — ensuring you only pay for resources you use while allowing your application to auto-scale as needed.
Here is a production-ready Lambda function that handles document analysis using Claude via Amazon Bedrock:
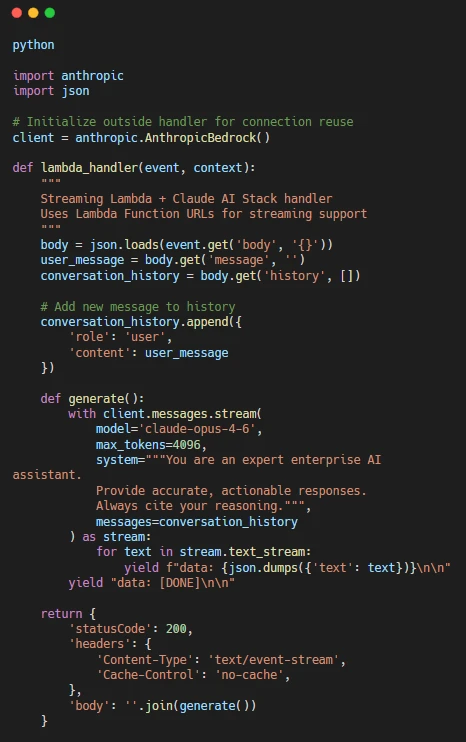
Streaming Responses for Better UX
For conversational AI applications where response time matters, Lambda supports streaming via Function URLs — bypassing API Gateway’s 29-second timeout limitation:
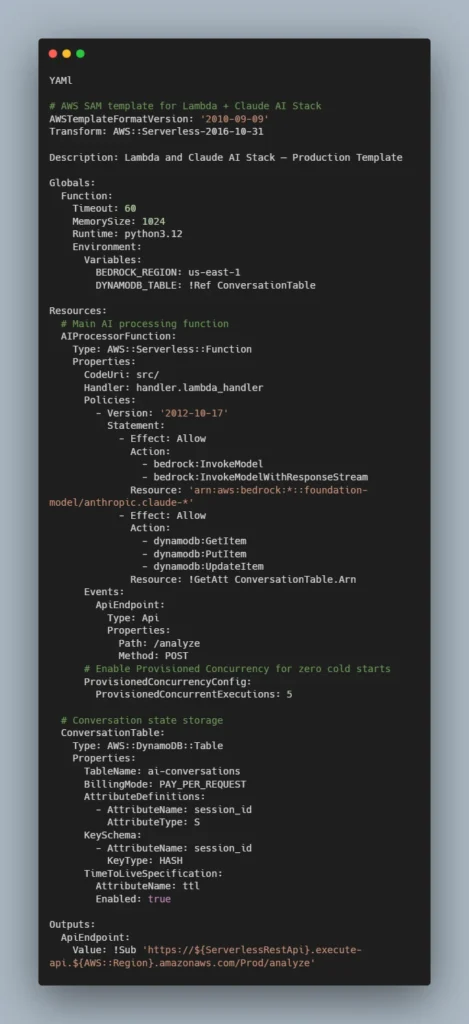
Infrastructure as Code: Complete SAM Template
Use Cases Where Lambda and Claude AI Stack Dominates
- Document Processing Pipelines: Trigger Lambda automatically when files are uploaded to Amazon S3. Use cases include document format conversion and CSV data ingestion into DynamoDB or RDS. Add Claude into that pipeline, and you have a fully serverless document intelligence system — PDF ingestion, text extraction, Claude analysis, structured output storage — with zero server management and pay-per-document pricing.
- Internal Knowledge Assistants: A consulting firm with 10,000 employees wanting an AI assistant that can answer questions using 20 years of project documentation is a perfect use case for the Lambda and Claude AI stack. Lambda handles the request routing and retrieval logic. Claude handles the reasoning and synthesis. DynamoDB maintains conversation context. The whole system scales from 1 user to 10,000 users without any infrastructure change.
- Scheduled AI Analysis Jobs: Replace traditional cron jobs with CloudWatch Events (EventBridge) triggers. Lambda functions can run database backups, generate nightly reports, clean up temporary files, or send scheduled notifications — all without maintaining a dedicated server. Add Claude, and these become intelligent analysis jobs — nightly competitive intelligence reports, weekly trend summaries, daily anomaly detection across business metrics.
- Compliance Monitoring Agents: Finance, healthcare, and legal teams running compliance monitoring workflows are perfect fits. Documents arrive via S3 event, Lambda triggers, Claude analyzes against compliance frameworks, results are written to DynamoDB, and alerts are pushed via SNS. The entire pipeline costs pennies per document and scales infinitely.
When Lambda and Claude AI Stack Is NOT the Right Choice:
Being direct about limitations makes this more useful than a one-sided argument:
Don’t use Lambda + Claude when:
- Your AI application runs continuous, high-volume inference at 1M+ requests per month — dedicated Bedrock provisioned throughput becomes cheaper.
- You need sub-100ms latency — even with Provisioned Concurrency, the Bedrock API call adds 300–800ms minimum.
- You require custom model fine-tuning with GPU access — Lambda doesn’t expose GPU controls.
- Your workflow runs longer than 15 minutes — Lambda’s maximum execution timeout.
Teams without dedicated ML infrastructure expertise benefit most — if your team is strong on ML modeling but weak on deployment, serverless lets you ship without becoming DevOps experts. Conversely, if your team already has deep AWS infrastructure expertise and you’re running at massive scale, you may find more cost efficiency with dedicated endpoints.
Industries Already Running This Stack in Production
- Financial Services — Transaction monitoring, document analysis for loan processing, and regulatory report generation. Lambda’s event-driven model maps naturally to financial event streams. Finance companies now run entire pipelines on serverless due to lower operational burden and predictable scaling.
- Healthcare — Patient intake processing, clinical documentation assistance, and insurance prior authorization analysis. This solution implements a serverless conversational AI system using a WebSocket-based architecture for real-time customer interactions — the same pattern applies directly to patient-facing healthcare applications.
- Legal Tech — Contract analysis pipelines, case document summarization, compliance review workflows. The S3-trigger-to-Lambda-to-Claude pattern handles entire case file libraries at per-document pricing.
- E-Commerce — Product description generation, review analysis, and customer support automation. Variable traffic patterns — Black Friday spikes, seasonal demand — are exactly where Lambda’s auto-scaling advantage is most valuable.
- SaaS Platforms — Any SaaS product adding AI features benefits from the Lambda and Claude AI stack because it lets them ship AI capabilities without managing AI infrastructure — keeping their team focused on product, not DevOps.
Conclusion: Lambda and Claude AI Stack Is the Default Choice in 2026 — Not the Alternative
The companies that win in 2026 won’t be the ones adopting the most services — they’ll be the ones building the tightest feedback loops. The Lambda and Claude AI stack enables exactly that: rapid iteration, zero infrastructure overhead, and cost structures that reward usage rather than punish it.
90% of AI workloads don’t need a dedicated server. They need an event trigger, an intelligent model, and a place to store state. Lambda, Claude, and DynamoDB handle all three — for a fraction of the cost of dedicated infrastructure, with better scalability and less operational complexity.
The teams still defaulting to “we need a server for this” when they mean “we need AI for this” are solving the wrong problem. The winning stack in 2026 is already built. The question is how quickly you deploy it.
About Orbilon Technologies
Orbilon Technologies is a cloud-native software engineering company that designs and deploys production AI systems on AWS. From Lambda-based agentic pipelines to full-stack SaaS platforms powered by Claude and GPT-5.4, our team in Lahore, Pakistan — with a growing US and UK client base — ships AI infrastructure that scales without the overhead of managing it.
If you’re building on the Lambda and Claude AI stack and need a team that knows the architecture cold — from SAM templates to Bedrock prompt caching to Provisioned Concurrency configuration — we deliver production-ready systems in weeks, not quarters.
- 4.96 on Clutch and GoodFirms.
- AWS-specialized AI engineering.
- Delivery in 30–90 days.
- Website:orbilontech.com
- Email:support@orbilontech.com
Ready to Build Your Lambda + Claude AI Stack?
Whether you’re architecting your first serverless AI application or migrating an existing AI workload off dedicated servers, Orbilon Technologies delivers the complete stack — architecture, code, deployment, and monitoring — in a single engagement. Book a Free Architecture Review.
Want to Hire Us?
Are you ready to turn your ideas into a reality? Hire Orbilon Technologies today and start working right away with qualified resources. We will take care of everything from design, development, security, quality assurance, and deployment. We are just a click away.

